
The neglected area of modularity: execution, settlement and aggregation layers
Original author: Bridget Harris
Original translation: Luffy, Foresight News
Not all components of the modular stack are created equal in terms of attention and innovation. While many projects have innovated on the data availability (DA) and ordering layers, only recently have the execution and settlement layers received significant attention as part of the modular stack.
Competition in the shared sorter space is spurred, with many projects such as Espresso, Astria, Radius, Rome, and Madara vying for market share, in addition to RaaS providers like Caldera and Conduit, which develop shared sorters for Rollups built on top of them. These RaaS providers are able to offer Rollups more favorable fees because their underlying business models do not rely entirely on sorting revenue. There are also many Rollups that choose to run their own sorter to capture the fees it generates.
The sorter market is unique compared to the DA space. The DA space is essentially an oligopoly consisting of Celestia, Avail, and EigenDA. This makes it difficult for smaller new entrants outside of the big three to successfully disrupt the space. Projects either leverage the “existing” choice (Ethereum); or choose one of the mature DA layers based on the type and consistency of their own technology stack. While there are significant cost savings from using a DA layer, outsourcing the sorter part is not an obvious choice (from a fee perspective, not security), mainly because of the opportunity cost of giving up sorter revenue. Many also believe that DA will become a commodity, but we see in crypto that super strong liquidity moats combined with unique (hard to copy) underlying technology make it extremely difficult to commoditize a layer in the stack. Regardless of these arguments, there are many DA and sorter products launched. In short, for some modular stacks, “there are several competitors for each service.”
I think the execution and settlement (and aggregation) layers are relatively underexplored, but they are starting to be iterated in new ways to better align with the rest of the modular stack.
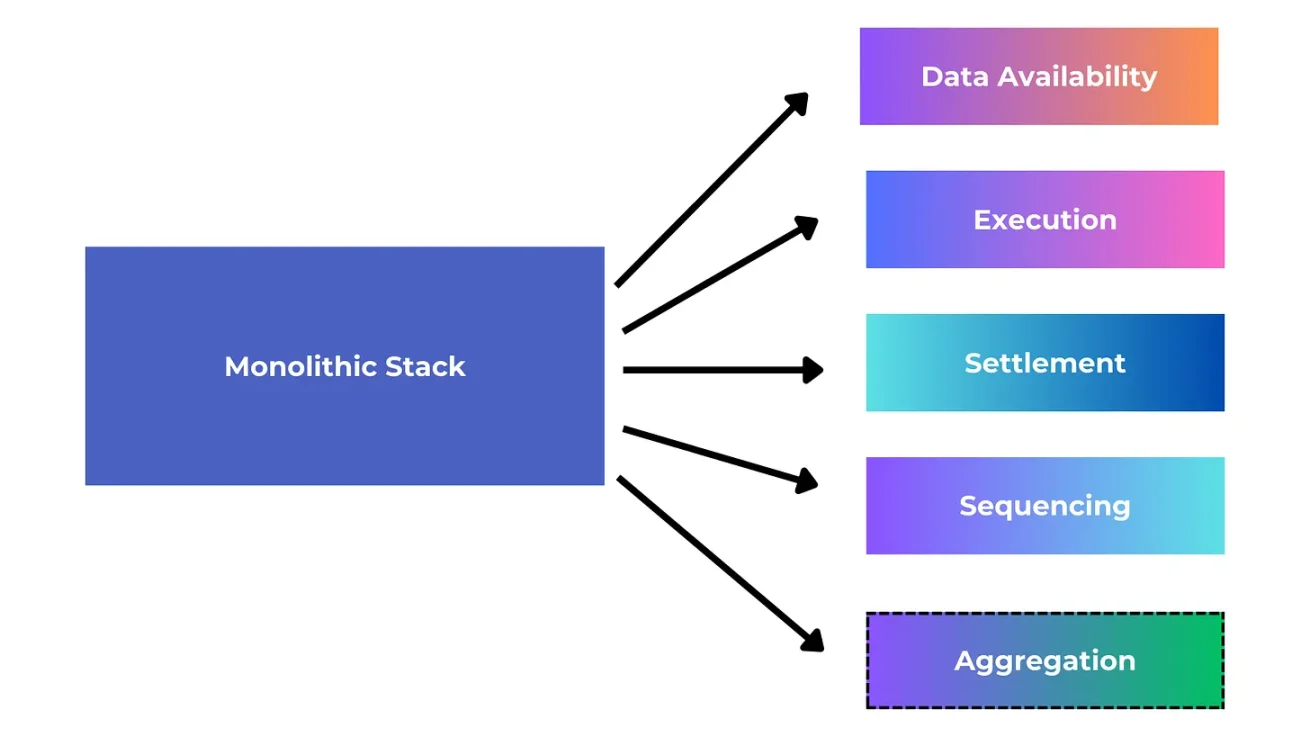
Execution and Settlement Layer Relationship
The execution layer and the settlement layer are tightly integrated, where the settlement layer can be used as a place to define the final results of state execution. The settlement layer can also add enhancements to the results of the execution layer, making the execution layer more powerful and secure. This may mean many different functions in practice, such as the settlement layer can serve as an execution layer to resolve fraud disputes, verify proofs, and connect other execution layers.
It is worth mentioning that some teams are supporting the development of custom execution environments directly in their own protocols, such as Repyh Labs, which is building an L1 called Delta. This is essentially the opposite design of the modular stack, but still provides flexibility in a unified environment, and has technical compatibility advantages because teams do not have to spend time manually integrating each part of the modular stack. Of course, the disadvantages are isolation from a liquidity perspective, the inability to choose the modular layer that best suits your design, and the high cost.
Other teams choose to build L1s for a core function or application. Hyperliquid is an example of a dedicated L1 built for its flagship native application (a perpetual contract trading platform). While their users need to cross-chain from Arbitrum, their core architecture does not rely on the Cosmos SDK or other frameworks, so it can be iteratively customized and optimized for its main use case.
Executive Level Progress
The only feature that general-purpose alt-L1s had over Ethereum in the last cycle was higher throughput. This meant that projects that wanted to significantly improve performance essentially had to choose to build their own L1 from scratch, mainly because Ethereum itself did not have the technology yet. Historically, this simply meant embedding efficiency mechanisms directly into the general-purpose protocol. In this cycle, these performance improvements are achieved through modular design, and on Ethereum, the dominant smart contract platform. This allows existing and new projects to take advantage of the new execution layer infrastructure without sacrificing Ethereum's liquidity, security, and community moat.
Currently, we are also seeing more and more mixing and matching of different VMs (execution environments) as part of a shared network, which provides developers with flexibility and greater customization on the execution layer. For example, Layer N allows developers to run general Rollup nodes (such as SolanaVM, MoveVM, etc. as execution environments) and application-specific Rollup nodes (such as perpetual DEX, order book DEX) on top of its shared state machine. They are also working on achieving full composability and shared liquidity between these different VM architectures, which is an on-chain engineering problem that has historically been difficult to accomplish at scale. Each application on Layer N can asynchronously pass messages without delay in consensus, which is usually the "communication overhead" problem of cryptocurrencies. Each xVM can also use a different database architecture, whether it is RocksDB, LevelDB, or a custom synchronous/asynchronous database created from scratch. Interoperability works in part through a "snapshot system" (an algorithm similar to the Chandy-Lamport algorithm), where the chain can asynchronously transition to a new block without system suspension. In terms of security, fraud proofs can be submitted if the state transition is incorrect. With this design, they aim to minimize execution time while maximizing overall network throughput.
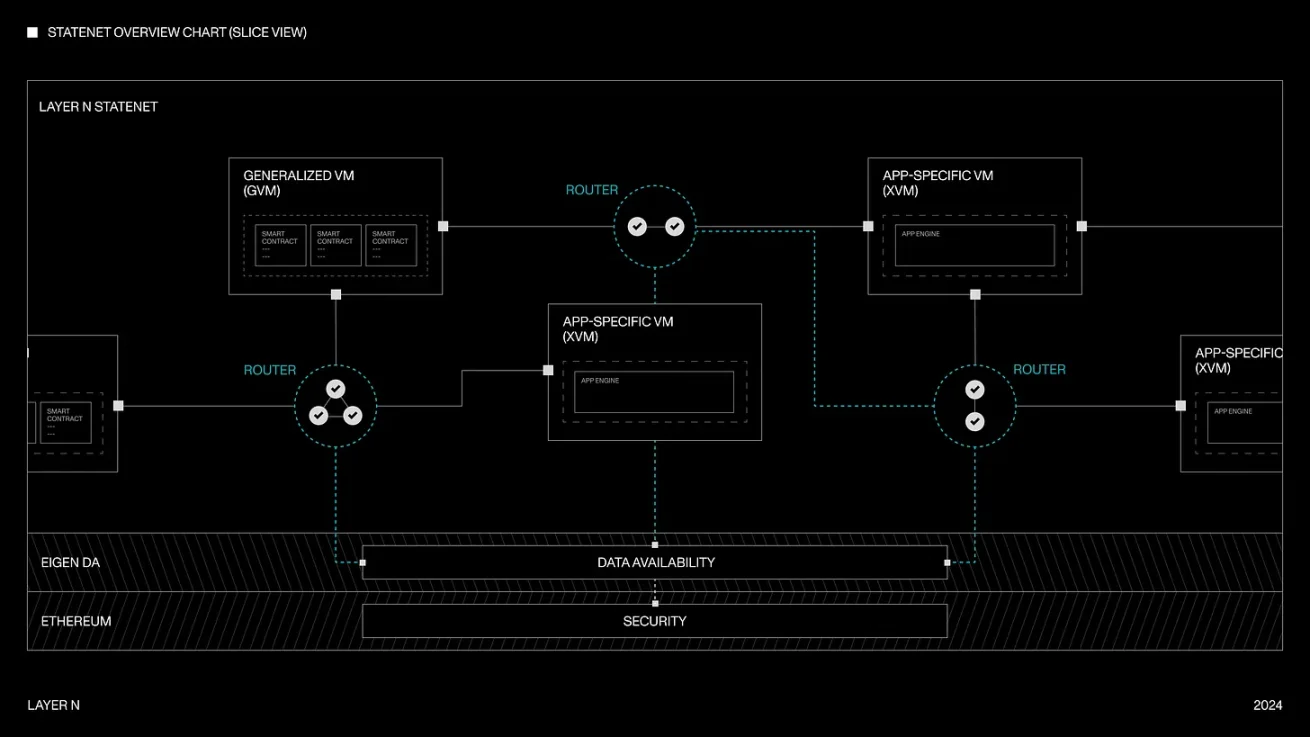
Layer N
To drive advancements in customization, Movement Labs leverages the Move language (originally designed by Facebook and used in networks like Aptos and Sui) for VM/execution. Move has structural advantages over other frameworks, primarily security and developer flexibility. Historically, these have been two major issues for building on-chain applications using existing technologies. Importantly, developers can also just write Solidity and deploy on Movement. To achieve this, Movement created a fully bytecode-compatible EVM runtime that can also be used with the Move stack. Their Rollup M 2 leverages BlockSTM parallelization, which allows for higher throughput while still being able to access Ethereum's liquidity moat (historically, BlockSTM has only been used on alt L1s like Aptos, which obviously lacks EVM compatibility).
MegaETH is also driving advancements in the execution layer space, particularly through its parallelization engine and in-memory database, where the sorter can store the entire state in memory. In terms of architecture, they leverage:
Native code compilation makes L2 performance even better (if the contract is more computationally intensive, the program can get a big speedup, if it is not very computationally intensive, you can still get about 2x+ speedup).
Relatively centralized block production, but decentralized block verification and confirmation.
Efficient state synchronization, where full nodes do not need to re-execute transactions, but they do need to be aware of state deltas so they can apply to their local database.
Merkle tree update structure (usually updating the tree takes up a lot of storage space), and their method is a new trie data structure that is memory and disk efficient. In-memory computing allows them to compress the chain state into memory, so when executing transactions, they don't have to go to disk, just to memory.
Another design that has been recently explored and iterated upon as part of the modular stack is proof aggregation: defined as a prover that creates a single succinct proof of multiple succinct proofs. First, let’s take a look at the aggregation layer as a whole and its history and current trends in crypto.
The value of the aggregation layer
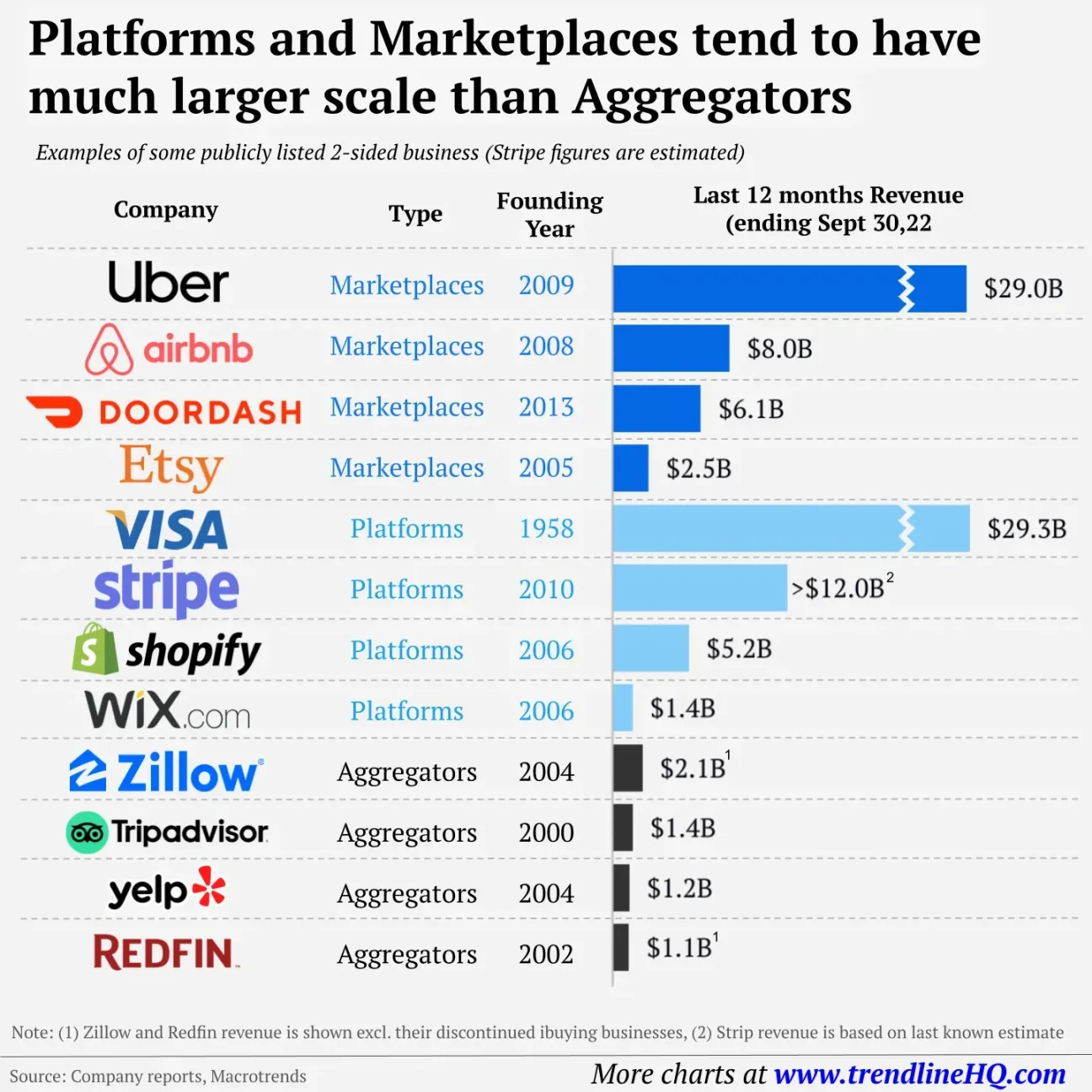
Historically, in non-cryptocurrency markets, aggregators have had smaller market share than platforms:
While I’m not sure this applies to all cases in cryptocurrencies, it does apply to decentralized exchanges, cross-chain bridges, and lending protocols.
For example, 1inch and 0x (two major DEX aggregators) have a combined market cap of ~$1 billion, a fraction of Uniswap’s ~$7.6 billion market cap. The same is true for cross-chain bridges: cross-chain bridge aggregators like Li.Fi and Socket/Bungee have a smaller market share than platforms like Across. While Socket supports 15 different cross-chain bridges, their total cross-chain transaction volume is actually similar to Across (Socket — $2.2 billion, Across — $1.7 billion), and Across only accounts for a small fraction of Socket/Bungee’s recent transaction volume.
In the lending sector, Yearn Finance is the first decentralized lending yield aggregation protocol, and its market value is currently about $250 million. In comparison, platforms such as Aave (about $1.4 billion) and Compound (about $560 million) have higher valuations.
The situation is similar in traditional financial markets. For example, ICE (Intercontinental Exchange) US and CME Group each have a market cap of about $75 billion, while “aggregators” like Schwab and Robinhood have market caps of about $132 billion and about $15 billion, respectively. At Schwab, which routes through numerous venues like ICE and CME, the proportion of volume routed through them is disproportionate to their market cap share. Robinhood has about 119 million options contracts per month, while ICE has about 35 million—and options contracts are not even a core part of Robinhood’s business model. Despite this, ICE is valued about 5 times higher than Robinhood in the public market. Therefore, as application-level aggregation interfaces that route customer order flow to various venues, Schwab and Robinhood are not valued as highly as ICE and CME despite their large trading volumes.
As consumers, we assign less value to aggregators.
This may not be true in crypto if the aggregation layer is embedded into the product/platform/chain. If the aggregator is tightly integrated directly into the chain, it is obviously a different architecture and I am curious to see how it will develop. One example is Polygon's AggLayer, which allows developers to easily connect their L1 and L2 into a network that aggregates proofs and enables a unified liquidity layer between chains using CDK.
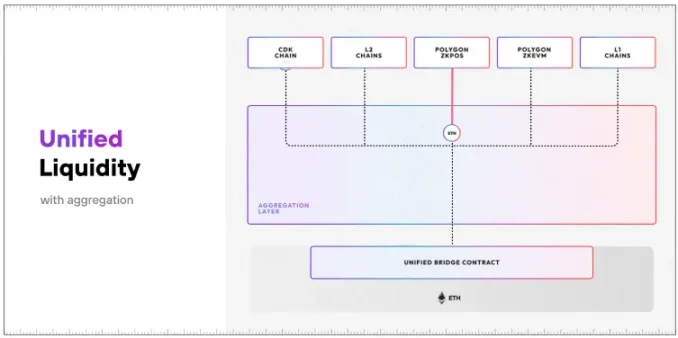
AggLayer
The model works similarly to Avail's Nexus interoperability layer, which includes proof aggregation and ordering auction mechanisms, making its DA product more powerful. Like Polygon's AggLayer, every chain or Rollup integrated with Avail can interoperate within Avail's existing ecosystem. In addition, Avail pools ordered transaction data from various blockchain platforms and Rollups, including Ethereum, all Ethereum Rollups, Cosmos chains, Avail Rollups, Celestia Rollups, and different hybrid structures such as Validiums, Optimiums, and Polkadot parachains. Developers from any ecosystem can build permissionlessly on top of Avail's DA layer while using Avail Nexus, which can be used for proof aggregation and messaging across ecosystems.
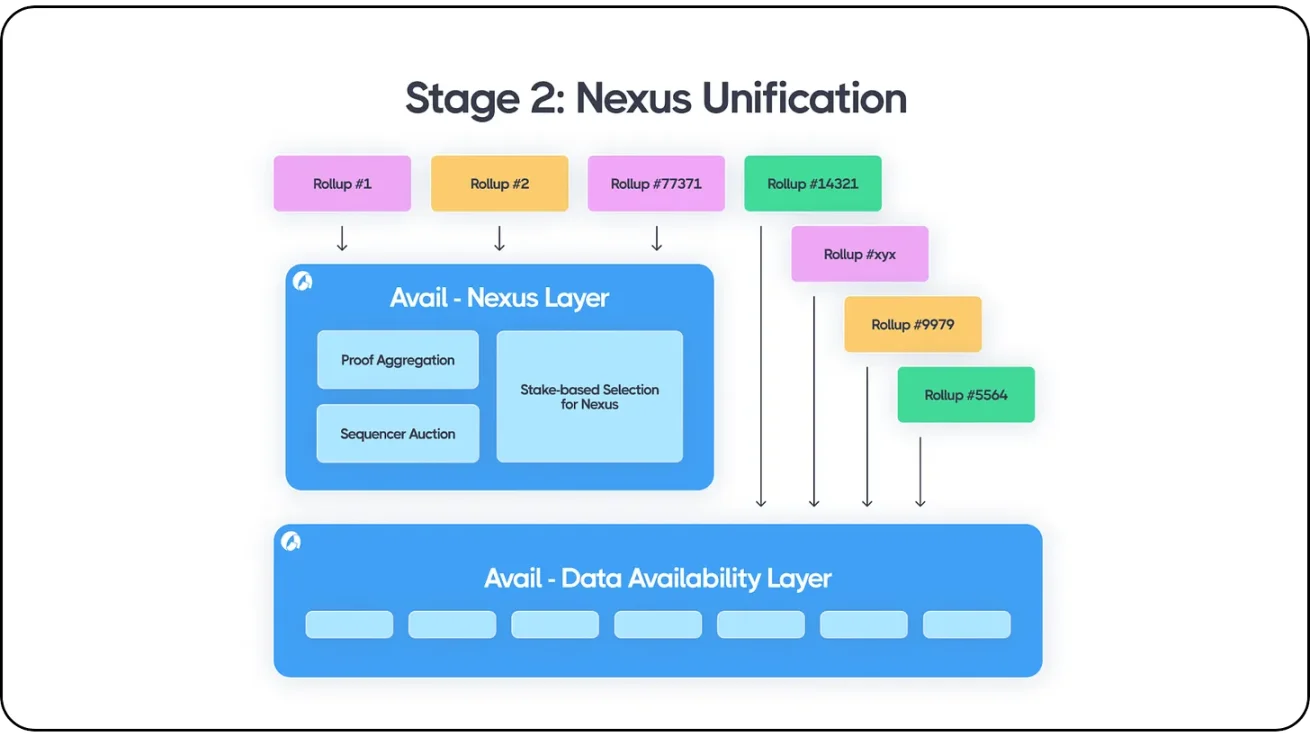
Avail Nexus
Nebra focuses on proof aggregation and settlement, which can aggregate between different proof systems. For example, aggregate the proof of system xyz and the proof of system abc so that you have agg_xyzabc (instead of aggregating within the proof system so that you have agg_xyz and agg_abc). The architecture uses UniPlonK, which standardizes the work of verifiers for circuit families, making it more efficient and feasible to verify proofs across different PlonK circuits. Essentially, it uses zero-knowledge proofs themselves (recursive SNARKs) to scale the verification part (which is usually the bottleneck in these systems). For customers, "last mile" settlement becomes easier because Nebra handles all batch aggregation and settlement, and the team only needs to change the API contract call.
Astria is working on some interesting designs around how their shared sorter works with proof aggregation. They leave the execution part to the Rollup itself, which runs the execution layer software on a given namespace on the shared sorter, essentially just an "execution API", a way for the Rollup to accept sorting layer data. They could also easily add support for validity proofs here to ensure that blocks do not violate the EVM state machine rules.
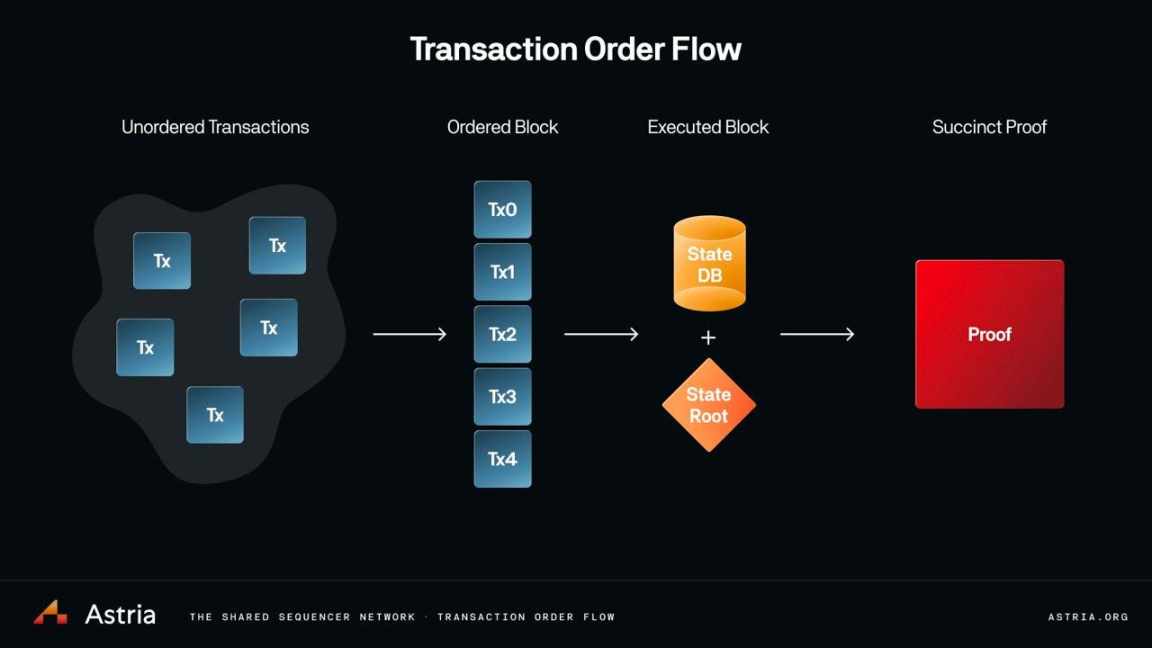
Here, products like Astria act as the #1 → #2 process (unordered transactions → ordered blocks), the execution layer/Rollup nodes are #2 → #3, and protocols like Nebra act as the last mile #3 → #4 (execution blocks → succinct proofs). Nebra could also be a theoretical fifth step, where proofs are aggregated and then verified. Sovereign Labs is also working on a similar concept to the last step, where cross-chain bridges based on proof aggregation are the core of their architecture.
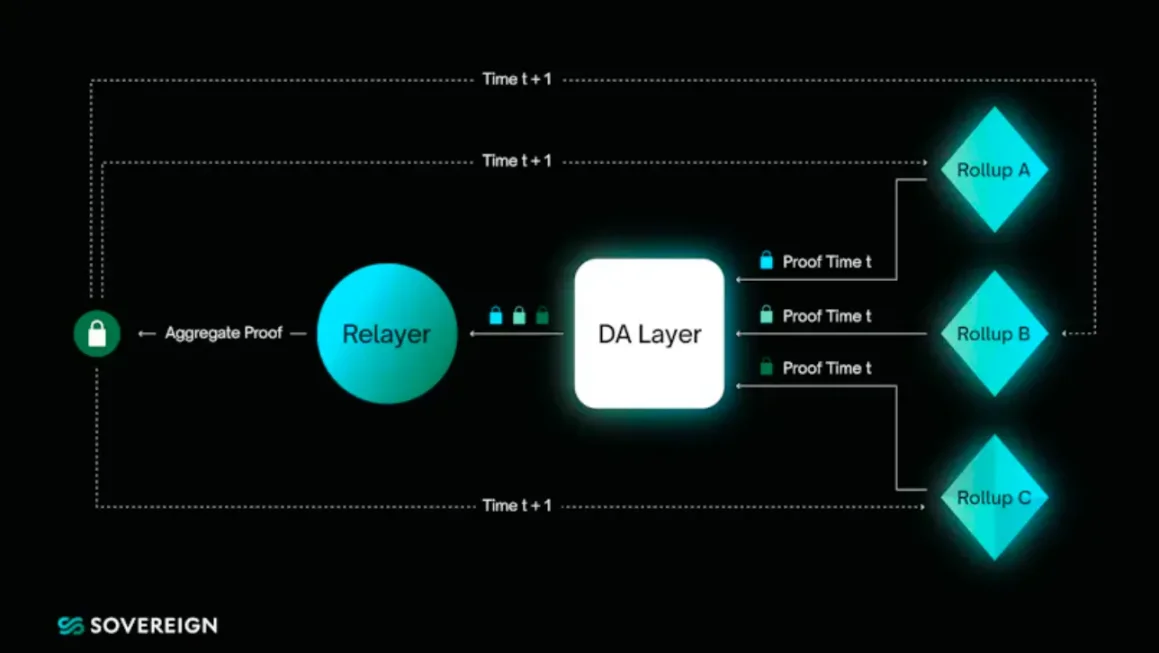
In general, some application layers are starting to own the underlying infrastructure, in part because if they don’t control the underlying stack, then keeping only the upper layer applications may bring incentive problems and high user adoption costs. On the other hand, as competition and technological progress continue to drive down infrastructure costs, it becomes cheaper for applications/application chains to integrate with modular components. I believe this dynamic will be stronger, at least for now.
With all of these innovations (execution layer, settlement layer, aggregation layer), greater efficiency, easier integration, greater interoperability, and lower costs become possible. All of this ultimately leads to better applications for users and a better development experience for developers. It's a winning combination that leads to more innovation, and faster innovation.


