
Buterin’s latest paper: How does the privacy pool protocol protect user privacy and meet compliance requirements?
Original: "Blockchain Privacy and Regulatory Compliance: Towards a Practical Equilibrium"
Authors: Vitalik Buterin, Jacob Illum, Matthias Nadler, Fabian Schar and Ameen Soleimani
Translation: Translated by Odaily
Today, Vitalik Buterin and others have jointly written a research paper on privacy protocols, titled "Blockchain Privacy and Regulatory Compliance: Towards a Practical Equilibrium".
The paper describes a new privacy-enhancing protocol based on smart contracts called the privacy pool. It discusses its advantages and disadvantages and demonstrates how it balances the needs of honest and dishonest users. The protocol aims to use zero-knowledge proofs to verify the legitimacy of users' funds without revealing their complete transaction history, while also balancing privacy and regulatory requirements by filtering out funds associated with criminal activities.
Odaily now presents the essence of the paper as follows:
I. Introduction
Public blockchains are designed to be transparent. The basic idea is that anyone can choose to verify transactions without relying on central third parties. By reducing dependencies, it provides a neutral foundation for various applications, including but not limited to finance and self-sovereign identity.
However, from a privacy perspective, public datasets contain every transaction with each blockchain address. Every time someone transfers assets to another address or interacts with a smart contract, that transaction will be permanently visible on the blockchain. This clearly does not meet privacy requirements.
For example, Alice pays for dinner at a restaurant using a blockchain wallet. The recipient now knows Alice's address and can analyze all past and future activities associated with that address. Similarly, Alice now knows the restaurant's wallet address and can use this information to obtain the wallet addresses of other customers or view the restaurant's revenue. Alternatively, third parties (such as social media) who know the restaurant and Alice's wallet address can easily deduce Alice's actual residential address and study her past and future transactions.
The rise of privacy enhancement protocols is to address the above issues. It allows users to deposit funds into a protocol, use one address, and extract funds from the protocol at a later point in time using another address. All deposits and withdrawals can still be seen on the blockchain, but the specific relationship between incoming and outgoing transactions is no longer public.
One of the most famous privacy enhancement protocols is Tornado Cash. It successfully solves the aforementioned problems and allows users to retain some privacy. However, in addition to legitimate users attempting to protect their data, Tornado Cash has also been used by various malicious actors. Evidence shows that hacker organizations have transferred funds through this protocol. There is evidence to suggest that North Korean hacker groups have also used this privacy enhancement protocol, ultimately leading to the smart contract address of this protocol being included in the U.S. Office of Foreign Assets Control (OFAC)'s list of specially designated nationals and blocked persons (commonly known as the SDN list).
The key issue with Tornado Cash is the blurry line between legitimate users and criminal users. Therefore, Tornado Cash provides a compliance feature that allows users to create evidence to prove which deposit a given withdrawal came from. While this mechanism does indeed allow people to prove their innocence, the cost is having to trust a centralized intermediary and creating information asymmetry. Ultimately, this mechanism is used by hardly any users.
This article discusses the extension of this approach, enabling users to publicly prove information about which deposits their withdrawals may come from without sacrificing privacy. The privacy pool introduces a general concept: allowing membership proofs ("I prove my withdrawal comes from a specific deposit") without revealing the specific deposit.
From one of these deposits") or exclusion proof ("I prove that my withdrawal does not come from any of these deposits"). This article discusses the proposal and explains how it can be used to achieve a balance between honest and dishonest users. Please note that privacy pools provide additional options by expanding the set of actions available to users. If needed, they can still provide more detailed proofs to specific counterparties. However, in some cases, membership or exclusion proofs may already be sufficient. Furthermore, the option to publicly publish these proofs has many advantages compared to bilateral disclosure. Second, Technical Background In this section, we provide a brief technical overview and discuss the technical construction and general principles of protocols such as Privacy Pools. 1. Blockchain Privacy Before ZK-SNARKs Historically, proponents of blockchain believed that despite all transactions being transparent, blockchain could protect privacy because they provided anonymity. With the emergence of modern clustering and analysis tools, this privacy protection has become insufficient. To improve the privacy of public blockchains, more powerful techniques such as token Join and Monero have been introduced. However, these technologies still carry the risk of data leaks. Subsequently, general zero-knowledge proof technologies such as Zcash and Tornado Cash emerged, which can make the anonymity set of each transaction equal to the entire set of previous transactions. This technology is commonly referred to as ZK-SNARKs. 2. ZK-SNARKs ZK-SNARKs is a technology that allows the prover to prove a mathematical statement about public data and private data while satisfying twoKey attributes: Zero knowledge and simplicity.● Zero knowledge: Apart from proving that the stated private data complies with the declaration, no information about the private data will be leaked.
● Simplicity: The proof is concise and can be quickly verified, even if the proven declaration requires time-consuming calculations.
ZK-SNARKs have gained significant attention in the blockchain community because of their importance in scalability, such as ZK-rollups. For privacy applications, simplicity is not particularly important, but zero knowledge is essential.
The "declaration" proven by ZK-SNARKs can be seen as a program type called a "circuit," which calculates the result of the function f(x, w) using public input and private input and then proves that for a given public input x, there exists a private input w such that the result of f(x, w) is True.
3. Applications of ZK-SNARKs in systems like Zcash and Tornado Cash
There are slight differences between different versions of Zcash and systems inspired by it, such as Tornado Cash. However, they rely on similar underlying logic. This section describes a simplified version that roughly corresponds to how these protocols work.
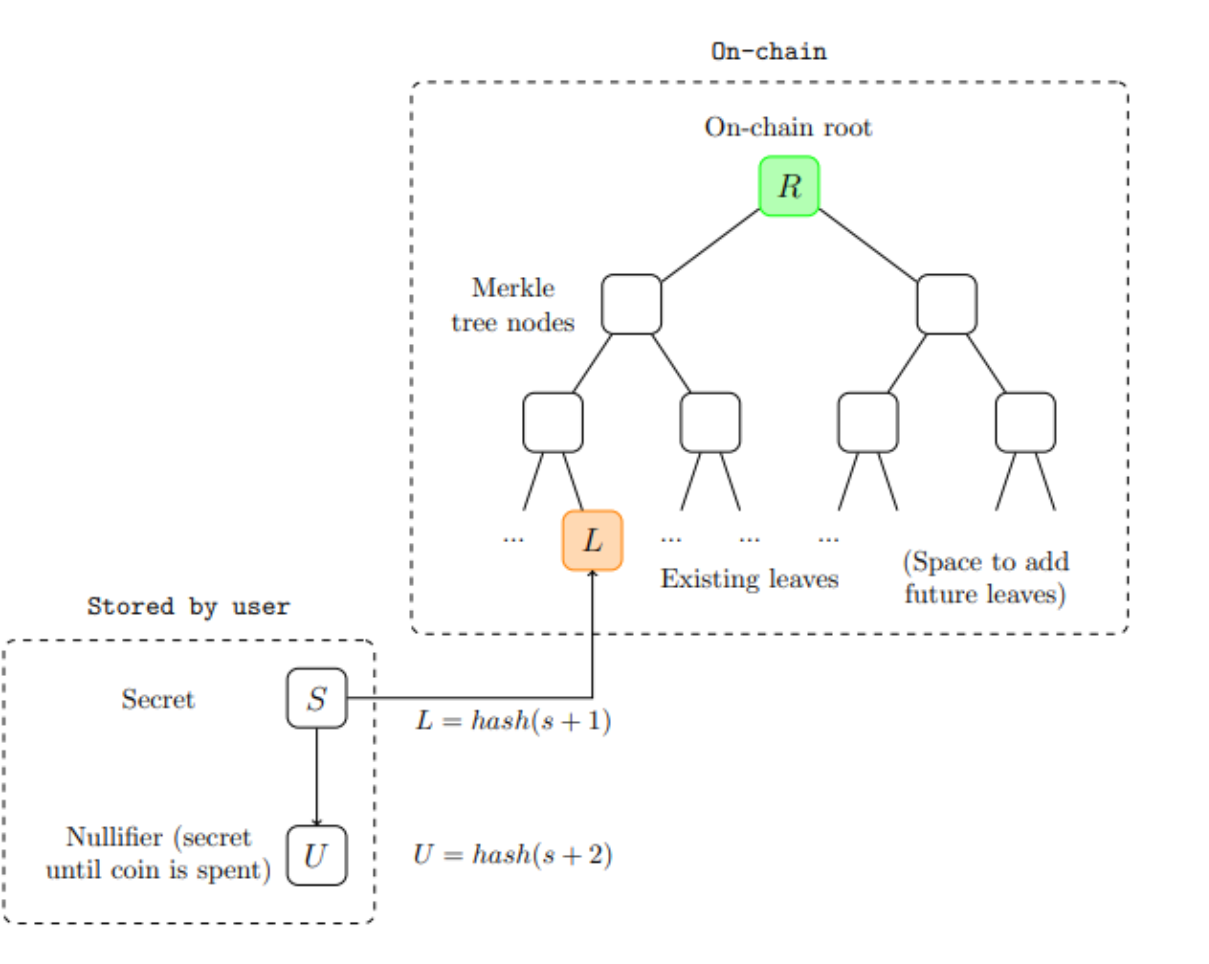
Tokens are composed of secret s held by their owners. Two values can be derived from s:
● Public token ID L = hash(s + 1)
● Nullifier U = hash(s + 2)
Here, hash refers to password hash functions, such as SHA 256. Given s, you can calculate the token ID and nullifier. However, given a set of nullifiers and public token IDs, the pseudo-random behavior of the hash function ensures that you cannot determine which nullifier is associated with which token ID unless you know the secret s used to generate both.
The blockchain tracks all token IDs that have been "created" as well as all nullifiers that have been "spent". Both of these sets are constantly growing (unless the protocol mandates when tokens must be spent).
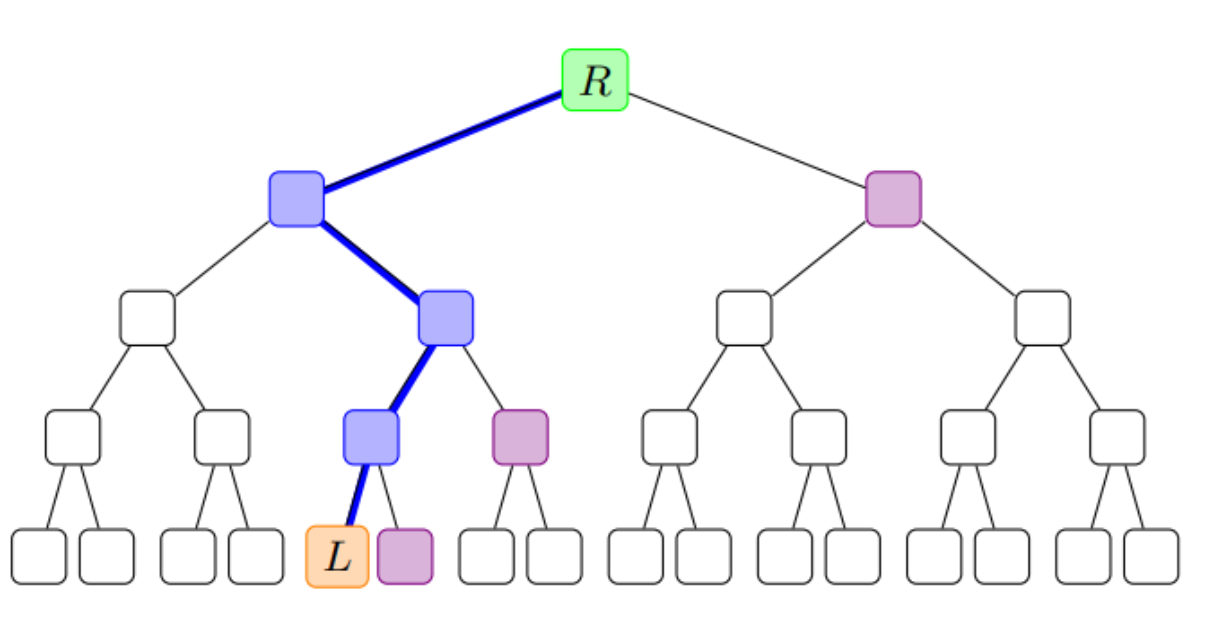
The set of token IDs is stored in a data structure called a Merkle tree: if the tree contains N items, each adjacent pair of items is hashed (resulting in ⌈ N/2 ⌉ hashes), and each adjacent pair of those hashes is hashed again (resulting in ⌈ N/4 ⌉ hashes), and so on, until the entire dataset is committed to a single "root hash".
Given a specific value in the tree and the root hash, a Merkle branch can be provided: the "sister values" that were hashed together at each step along the path from that value to the root. This Merkle branch is extremely useful as it is a small (log 2(N) hashes) piece of data that can be used to prove that a specific value is indeed in the tree. The diagram below shows an example of a Merkle tree with a height of 4.
When users send coins to others, they provide the following:
● The zerostate U to be spent
● The token ID L' of the new token they want to create (the recipient is required to provide this)
● A ZK-SNARK.
The ZK-SNARK contains the following private inputs:
● The secret s of the user
● A Merkle branch of the token ID tree to prove that the token ID is L = hash(s + 1) was actually created at some point in the past
It also contains the following public inputs:
● U, the zerostate of the token being spent
● R, the root hash that the Merkle proof is against
The ZK-SNARK proves two properties:
● U = hash(s + 2)
● Merkle branches are valid.
In addition to ZK-SNARK, the protocol also checks the following:
● R is the current or historical root hash of the token ID tree.
● U is not in the spent nullifier set.
If the transaction is valid, it will add "U" to the spent zeroizers collection and add "L" to the token ID list. Showing "U" prevents a single token from being double-spent. However, no other information is revealed. The external world can only see when the transaction is sent; they cannot obtain patterns about who sends or receives these transactions, and cannot distinguish the unified source of tokens.
The above pattern has two exceptions: deposit and withdrawal. In deposit, a token ID can be created without invalidating a previous token. From a privacy perspective, deposit is not anonymous as the association between given "L" and external events that allow adding "L" is public (in Tornado Cash, it is depositing ETH into the system; in Zcash, it is newly mined ZEC).
In other words, deposit is associated with its past transaction history. In withdrawal, a zeroizer is consumed without adding a new token ID. This might disconnect the withdrawal from the corresponding deposit and indirectly disconnect it from past transaction history. However, the withdrawal can be associated with any future transactions that occur after the withdrawal event.
The initial version of Tornado Cash did not have the concept of internal transfers, it only allowed deposits and withdrawals. Later versions, still in experimental stages, also allow internal transfers and support tokens of various denominations, including support for "split" and "merge" operations. We will discuss in later chapters on how to extend the basic privacy-preserving token transfer system and privacy pool to arbitrary denominations.
4. ZK-SNARKs in Privacy Pool
The core idea of the privacy pool is that users not only prove the withdrawal is associated with a previous deposit through zero knowledge proofs, but also prove that it belongs to a stricter set of associations. The association set can be a subset of all previous deposits made or it can beIt is a collection that contains only the user's own deposits, or any collection in between. Users specify the collection by providing the Merkle root of the associated collection as public input. As shown in the diagram below, for simplicity, we do not directly prove that the associated collection is indeed a subset of the previous deposits; instead, we only require users to use the same coin ID as the leaf nodes and prove with zero-knowledge proofs for two Merkle branches: - The Merkle branch of the root R of the total coin ID collection. - The Merkle branch of the provided associated collection root RA.
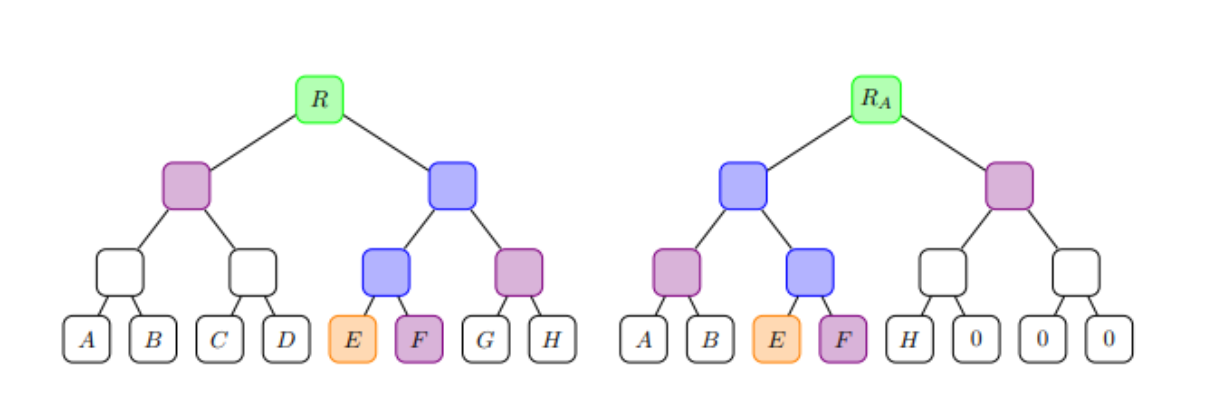
The intention of doing this is to place the complete association set somewhere (could be on-chain). The core concept is: not requiring users to accurately specify which deposit their withdrawal comes from, or, on the other extreme, providing no other information except proving no double spending, we allow users to provide a set of options that could be the source of funds, and this set can be chosen as wide or narrow as they wish.
We encourage the formation of an ecosystem that makes it easier for users to specify association sets that align with their preferences. The remaining part of this article will only describe the infrastructure based on this simple core mechanism and its consequences.
III. Practical Considerations and Use Cases
An analysis of how privacy-enhancing protocols are used in practice.
1. Use Cases of Association Sets
To illustrate the value of this scheme in an enforcement context, let's take an example:
Suppose we have five users: Alice, Bob, Carl, David, Eve. The first four users are privacy-conscious users who are honest and law-abiding, while Eve is a thief. Because the information that coins from addresses marked as "Eve" is stolen is known to the public, Eve is identified as the thief. In practice, this situation occurs frequently: on a public blockchain, funds generated by exploiting vulnerabilities in DeFi protocols are traced and labeled, thus identifying illegal funds flowing into Tornado Cash.
When each of these five users makes a withdrawal, they can choose to specify which association set. Their association set must include their own deposits, but they can choose to include which other addresses freely. The motivation of the first four users is, on the one hand, they want to maximize the protection of their privacy. This leads them to prefer to make their association set larger. On the other hand, they hope to reduce the chance of their coins being viewed as suspicious by merchants or exchanges. There is oneA simple way to achieve this is: They do not include Eve in their set of associations. So, for the four of them, the choice is clear: to make their set of associations {Alice, Bob, Carl, David}.
Of course, Eve also wants to maximize her set of associations. But she cannot exclude her own deposit, so she is forced to make her set of associations equal to the set of all five deposits. The participants' choices for their set of associations are shown in the following figure.

Although Eve herself did not provide any information, a clear inference can be drawn through a simple process of elimination: the fifth step of withdrawal can only come from Eve.
2. Construction of Associated Sets
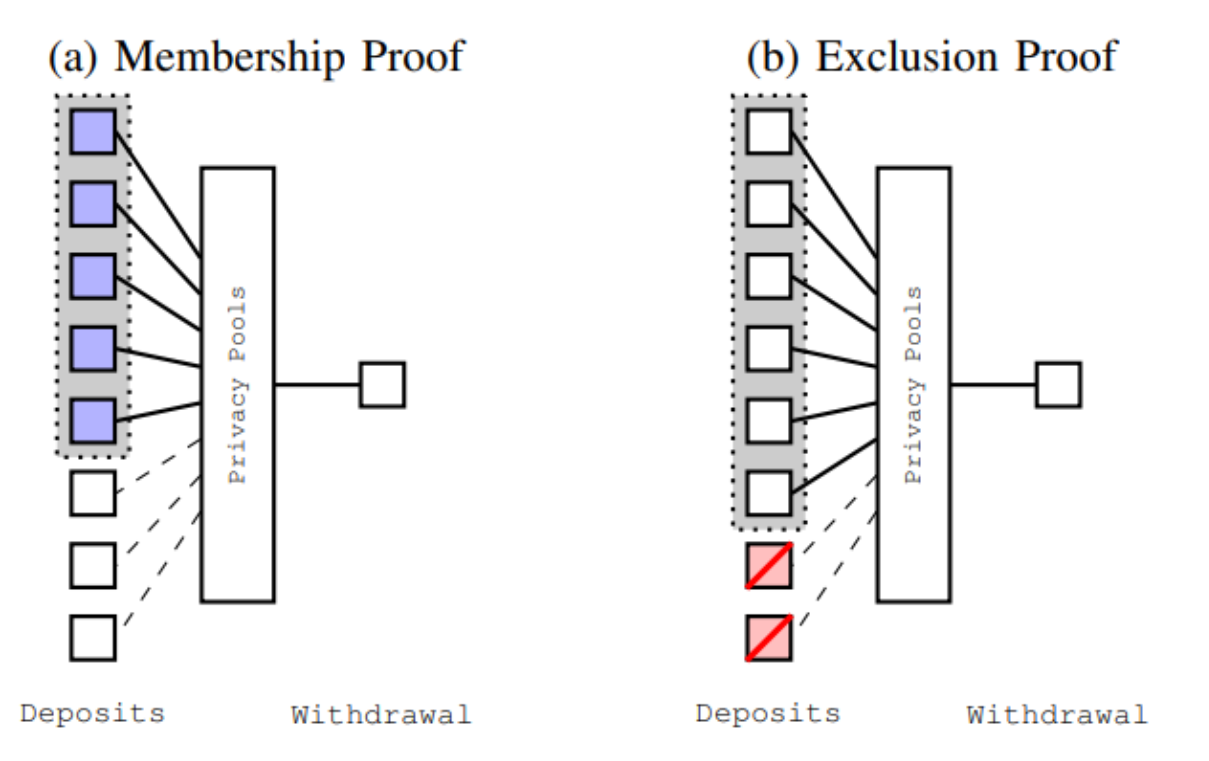
The previous section explained one possible way to use associated sets in a protocol similar to a privacy pool, as well as how honest participants can separate themselves from malicious participants. Note that the system does not rely on the altruism of Alice, Bob, Carl, and David; they have clear incentives to prove their separation. Now let's take a closer look at the construction of associated sets. In general, there are two main strategies to generate associated sets. They are described below and visualized in the diagram below.
● Inclusion (or Membership): Identify a specific set of deposits for which we have concrete evidence that they are low-risk, and construct an associated set that only includes these deposits.
● Exclusion: Identify a specific set of deposits for which we have concrete evidence that they are high-risk, and construct an associated set that includes all deposits except for these.
In practice, users do not manually select the deposits to be included in their associated collections. Instead, users subscribe to intermediaries we call Associated Collection Providers (ACPs), who generate associated collections with specific attributes. In some cases, ACPs can be built entirely on-chain without the need for manual (or AI) intervention. In other cases, ACPs independently generate associated collections and publish them on-chain or elsewhere.
We strongly recommend publishing at least the Merkle root of the associated collection on-chain; this eliminates the ability for malicious ACPs to attack users in certain ways (e.g., providing different associated collections to different users in an attempt to deanonymize them). The entire collection should be made available through APIs or ideally through a low-cost decentralized storage system like IPFS.
The ability to download the entire associated collection is important as it allows users to locally generate proof of membership without disclosing any additional information to the ACP, or even revealing the deposits corresponding to their withdrawal.
Here are the possible ways ACPs can be built in practice:
● Delayed inclusion, exclusion of bad actors: Any deposit will automatically be added to the associated collection after a fixed period of time (e.g., 7 days), but if the system detects any deposit associated with known malicious behavior (such as large-scale theft or addresses on government-sanctioned lists), it will never be added. In practice, this can be achieved through community-curated collections or existing transaction filtering service providers that have already performed the identification and tracking of deposits related to malicious behavior.
● Individual monthly fee: To join the associated collection, the value of the deposit must be below a fixed maximum value, and the depositor must prove possession of certain identity verification tokens with zero-knowledge (e.g., government-backed national ID systems or lightweight mechanisms like social media account verification). An additional parameter mixed together indicating the current month's deprecation symbol should be used.
To ensure that each identity can only submit a deposit to the associated pool once a month, the design aims to implement the spirit of many common anti-money laundering rules, where small payments below a certain threshold allow for higher levels of privacy. Note that this can be fully implemented as a smart contract without the need for manual supervision to maintain ongoing operation. ● Trusted community members' monthly fees: Similar to the individual monthly fees but with stricter limitations, users must prove themselves as highly trusted members of the community. Highly trusted community members agree to provide each other with privacy. ● AI-based real-time scoring: The AI ASP system can provide real-time risk scores for each deposit, and the system will output an associated pool containing deposits with risk scores below a certain threshold. Potentially, the ASP can output multiple pools corresponding to multiple risk score thresholds. Section IV: Further Technical Details In this section, we will analyze how the proposal supports arbitrary denominations and discuss special cases such as re-proving, bilateral direct proofs, and sequential proofs. 1. Support for arbitrary denominations The simplified privacy coin system mentioned above only supports transfers of coins with the same denomination. Zcash supports arbitrary denominations by using the UTXO model. Each transaction can have multiple inputs (requiring a zero-knowledge proof for each input) and multiple outputs (requiring a token ID for each output). Each created token ID must be accompanied by an encrypted denomination value. In addition to proving the validity of zero-knowledge proofs, each transaction must also include additional proofs that the sum of denominations of created coins does not exceed the sum of denominations of spent coins. The following diagram illustrates this additional proof.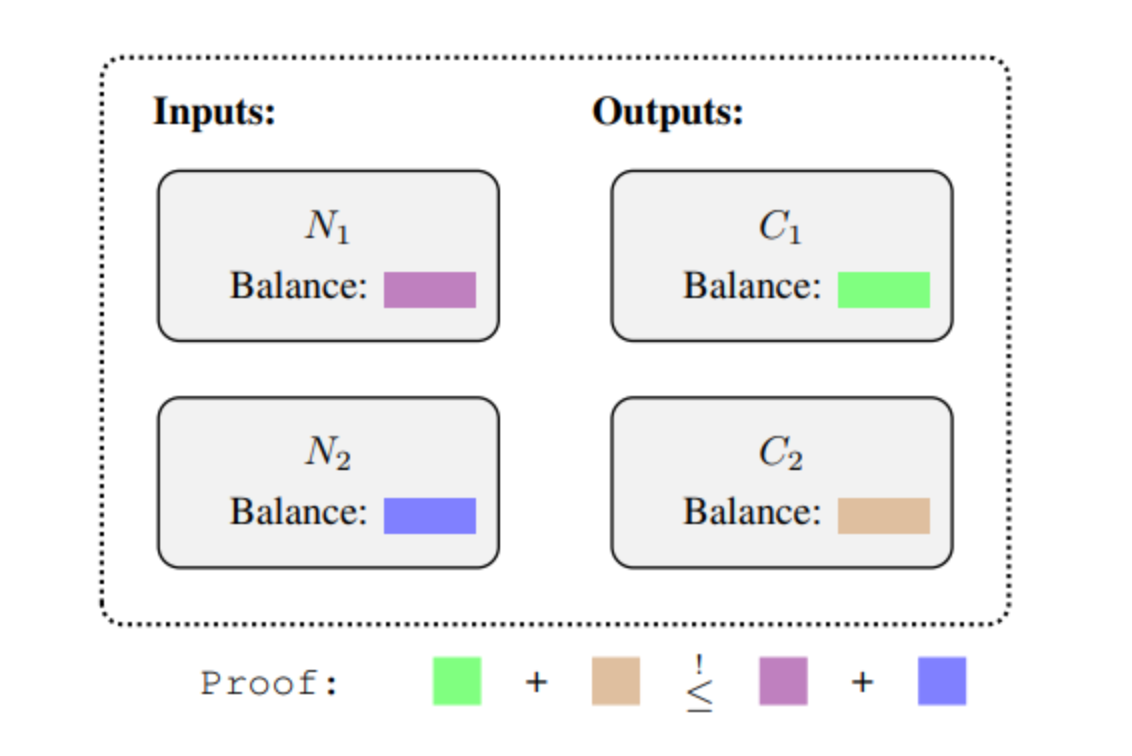
This design can be extended to support deposits and withdrawals by treating deposits as (non-encrypted) inputs and withdrawals as (non-encrypted) outputs. Additionally, for the purpose of simplifying analysis, the design can be constrained. For example, only partial withdrawals can be allowed, resulting in a transaction with one encrypted input and two outputs: one representing the unencrypted output of the withdrawal, and one representing the encrypted "change" output for future withdrawals.
A natural question is how to extend this design to support privacy pools. Simply inserting it into a privacy pool as is not ideal, as the transaction graph would be inconsistent with our intuitive expectations: if a user deposits 10 tokens and then spends 1 + 2 + 3 + 4 tokens in four consecutive withdrawals, we would like to consider all four withdrawals as originating from the original deposit of 10 tokens. But in reality, the result obtained is as shown in the following figure: the source of the first withdrawal is the deposit of 10 tokens, then the source of the second withdrawal is the change output of 9 tokens created by the first withdrawal, and so on. This poses a problem in practice as it requires an ASP to validate intermediate deposits and add them to its associated collection.

To be able to have the original 10 coins deposit as the source for all four withdrawals in this example, we need to address two issues:
● Ensure that each partial withdrawal is not openly associated with other withdrawals
● Allow each partial withdrawal to be a member of its associated set of deposits
If we only support partial withdrawals instead of more complex multiple-input multiple-output transactions and ensure that each withdrawal has a single, well-defined corresponding "original deposit," there are multiple direct ways to achieve this. One natural and scalable approach is to commit some information through transactions. For example, we can require transactions to include a commitment hash(coinID+hash®), where a random value r is included for blinding, and require ZK-SNARK proofs that the commitment in the transaction matches that of its parent transaction. If the parent transaction itself is a withdrawal, the commitment matches the coin ID of the original deposit, and if the parent transaction is a deposit, the commitment matches the coin ID of the initial deposit. Therefore, every transaction in the chain must include a commitment to the coin ID of the original deposit and needs to prove that this value is in the associated set provided by the transaction.
To enhance privacy against balance-totaling attacks, we can also support coin merging. For example, if I have some coins left, I can merge them together in the next deposit. To accommodate this scenario, we can require transactions to commit to a set of coin IDs and require transactions with multiple inputs to commit to the union of their parent transactions. A withdrawal will include a proof that all the committed coin IDs are in its associated set.
2. Special Cases
● Re-proving: Users need secret deposit information to extract class.Deposit in the Privacy Pool Protocol. The same secret information is also used to construct proofs of membership in the associated set. Preserving secret information allows users to generate new proofs to adapt to different sets or updated associated sets. This gives users greater flexibility but may also bring additional risks. ● Direct bilateral proof: In some cases, users may need to disclose the exact source of a withdrawal to another party. Users can create an associated set that only includes their own deposits and generate proofs for that set. These proofs are usually exceptional cases and contribute to partial privacy only when shared between parties. However, shared proofs require a strong assumption of trust. ● Sequential proof: In a fast transaction economy that uses a privacy pool system, modifications to the protocol are required to accommodate this environment. In addition to deposit and withdrawal transaction types, the protocol also needs to support internal transfer operations to improve efficiency. Furthermore, by passing Merkle branches and keys, users can propagate information related to transaction history for the recipient to verify the source of funds. This ensures that each user receives the minimum required information to have confidence in the received funds. In practice, a token may have multiple "sources". For example, Bob, a coffee stall owner, receives 5 tokens from Alice, 4 tokens from Ashley, and 7 tokens from Anne, and at the end of the day, he needs to pay Carl 15 tokens for dinner. On the other hand, David may receive 15 tokens from Carl, 25 tokens from Chris, and wish to deposit 30 tokens to Emma (an exchange). In these more complex scenarios, we follow the same principle: historical data that has been added to the associated set early enough can be ignored, while more recent data needs to be propagated. More details: Similar privacy pool systems can provide users with additional protection for their financial transaction data privacy while maintaining the ability to separate proofs from known illegal activities. It is expected that honest users will be incentivized by combining two factors.Participate in this scheme:
● Desires for privacy
● Desires to avoid suspicion
1. Social consensus and associated sets
If there is a complete consensus on judging the quality of funds, the system will create a simple separation balance. All users who possess "good" assets have a strong incentive and ability to prove that they belong to an "only good" associated set. On the other hand, malicious participants will be unable to provide this proof. They can still deposit "bad" funds into the pool, but this will not bring them any benefits. Each person can easily determine that the funds are extracted from a protocol that enhances privacy and see that the withdrawal references an associated set that contains deposits from suspicious sources. More importantly, "bad" funds will not taint "good" funds. When withdrawing funds from legitimate deposits, their owners can simply exclude all known "bad" deposits from their associated set.
In cases where there is global consensus and whether funds are considered "good" or "bad" depends on social perspectives or conclusions of legal jurisdictions, there may be significant differences in associated sets. Let's assume there are two legal jurisdictions with different sets of rules, A and B. Entities under both jurisdiction A and jurisdiction B can use the same privacy-enhancing protocol and choose to provide proofs that satisfy their respective legal requirements. Both can easily achieve privacy within their own associated sets and exclude withdrawals that do not meet their respective legal requirements. If necessary, membership proofs can be issued for the intersection of the two associated sets to reliably demonstrate that deposits corresponding to their withdrawals comply with the requirements of both legal jurisdictions.
Therefore, this proposal is extremely flexible and should be considered as neutral infrastructure. On one hand, it resists censorship. It allows anyone to join their chosen associated set and maintain privacy within their own community. On the other hand, external parties can request proofs for specific associated sets that comply with their regulatory requirements. Thus, even if a community with a malicious participant exists within the privacy-enhancing protocol, as long as the information accurately reflects in the construction of the associated set, they will not be able to conceal the suspicious origins of the deposits.
2. Properties of associated sets
Associated collections need to have certain attributes to be effective. The collections need to be accurate and precise so that users can trust the secure use of funds after withdrawal. Additionally, the attributes of each collection should be stable, meaning that there is a low likelihood of them changing over time. This reduces the need to re-validate withdrawals for new collections. Lastly, in order to achieve meaningful privacy protection, associated collections should be large enough and contain various types of deposits. However, these characteristics can conflict with each other. Generally, larger and more diverse collections may have better privacy attributes but may be less accurate and stable, while smaller collections are easier to maintain but provide less privacy.
3. Practical Considerations and Competition
Regulated entities accepting encrypted assets must ensure that their laws and regulations permit them to accept such funds. Today, many of these entities rely on so-called transaction screening tools: software or services that analyze the blockchain to identify potential suspicious activities, connections to illicit addresses, or other non-compliant transactions. Screening tools often express the risks associated with each transaction via risk scores. These scores are based on the destination of the transferred funds and their transaction history. In this regard, privacy-enhancing protocols can bring challenges. They eliminate the visible links between deposits and withdrawals. Consequently, with the presence of privacy-enhancing protocols, risk scores need to be considered and allocated based on the associated collections.
The tools and services for transaction screening are primarily provided by professional companies with expertise in blockchain analysis and relevant legal fields. Ideally, these companies (along with anyone else) should have access to all membership proofs and their corresponding associated collections in order to provide accurate risk scores for all transactions. Therefore, we recommend that all proofs be stored in a blockchain or other publicly accessible proof repository. The only exception would be single membership proofs shared with specific transaction parties. For obvious reasons, these proofs should not be publicly available.
Storing proofs directly on the chain increases additional transaction costs but reduces coordination efforts, makes competition fairer, and mitigates the risks of near-monopolies for screening tool providers due to exclusive knowledge of non-public proofs.
The general setup of privacy pools is highly flexible. By creating specific associated collections, the protocol can be customized for various use cases. Here are two examples of these special associated collections:
● A commercial banking alliance can create an associated collection that only includes customer deposits. This can ensure that any proof created for withdrawals is already familiar with the customer information (KYC) and anti-money laundering(AML) program, but does not reveal which withdrawal belongs to which customer.
● In cases where financial intermediaries need to clearly record the source of funds, they may request users to provide proof for associated collections that only include user deposits. Then, this proof will be exchanged bilaterally with the intermediary, allowing them to trace the funds as if the user had never used the privacy pool. While this requires users to trust that the intermediary will not disclose the proof, ideally it allows users to comply with regulations without having to disclose information to the public.
4. Design Choices and Alternative Solutions
The setting based on associated collections, zk proofs, and voluntary disclosure is highly flexible. While this is useful for ensuring that the proposal can adapt to different jurisdictions, caution should be exercised in specific design choices. In particular, there are two potential adjustments that we oppose. We believe they present trust requirements issues and may create a quasi-monopolistic market structure. Below, we briefly describe and discuss these alternative approaches:
● Centralized Access: Law enforcement agencies, crypto risk scoring providers, or similar participants can be granted permission to view the links between user transactions while keeping others' privacy intact.
● System-wide Whitelisting: Privacy systems can restrict the types of users that can deposit coins into their pools, requiring them to provide additional proof or requiring deposits to wait for a period during which centralized risk scoring systems can deny the deposit.
These two approaches are similar in that they grant specific entities privileges. This raises complex governance issues: Who can access this information? Who has the power to manage permissions? Private companies do not seem like a good choice, as any privilege can lead to an oligopolistic market structure, with a few companies having access to data that can provide these services while others cannot compete.
Similarly, when granting power to public institutions, many governance and political issues will be faced, particularly in an international setting. Even if up until now, an institution is 100% trustworthy, does not abuse power to pursue political agendas, and does not rely on other entities that may force it to abuse power, this is a static representation. Over time, organizations, members, countries, and political structures within organizations will change. There may be external pressures that these specificThe existence of power may generate additional incentives to disrupt and gain influence over the organization's governance system.
Furthermore, attacks from within or outside the organization, or errors made by centralized entities representing it, can have significant consequences. We believe that the creation of such centralized points of failure should be prevented.
That being said, we acknowledge that different transaction sizes and circumstances may require different proof combinations. For example, for large transactions, many users might ultimately provide basic exclusion proofs on-chain and offer more detailed information about the source of funds to their transaction counterparts.
5. Directions for further research
While this paper provides an overview of how zkSNARK-based privacy-enhancing protocols can be used in a regulated environment, there are several aspects worth further investigation.
Firstly, it is important to note that the privacy obtained through these protocols depends on various factors. Attackers may be able to link withdrawals to specific deposits due to insufficiently large association sets, improper root selection, and user errors.
In addition, the choices made by other users may have adverse effects on your own privacy. In extreme cases, all the others in the pool may publish a membership proof of size one, revealing a direct link between their deposits and withdrawals. This would implicitly disclose the remaining unique links between deposits and withdrawals. In a more subtle example, constraints from various membership proofs can be used to extract information and potentially correlate deposits and withdrawals with a high probability. Once this information from the proofs is combined with transaction metadata, the privacy properties of the protocol may be compromised.
Lastly, malicious ASes may choose to compile the proposed association sets in a way that allows them to extract information maximally or increase perceived anonymity by adding known corresponding deposits to withdrawals. All these issues require further research to assess the privacy properties provided. Similarly, it would be interesting to conduct further research into the properties of separation of balances, modeling the behavior of good and bad participants under specific assumptions, and how the public proofs of the former affect the privacy of the latter.
Legal experts can further examine specific disclosure requirements. The scheme proposed in this paper is highly flexible, and insights from legal experts can help tailor the protocol and the ecosystem built around it to ensure compliance in different legal jurisdictions.
Sixth, Conclusion
In many cases, privacy and compliance are considered to be conflicting. This article proposes that if privacy-enhancing protocols enable users to prove certain attributes of their financial sources, this may not be the case. For example, suppose users can prove that their funds are not associated with known illicit deposits, or prove that these funds are part of a specific deposit set without revealing any further information.
Such a setup can result in a separation equilibrium, where honest users are strongly incentivized to prove their membership in a compliant association and maintain privacy within that association. In contrast, dishonest users are unable to provide such proof. This allows honest users to disassociate themselves from third-party deposits that they disagree with or prevent them from using the funds in a compliant environment. We believe that this proposal is highly flexible and can be adjusted based on various potential regulatory requirements.
This article should be seen as a contribution to the potential coexistence of financial privacy and regulation in the future. We hope to foster discussions and steer the conversation in a more positive and constructive direction. Collaboration between practitioners, scholars from various disciplines, decision-makers, and regulatory agencies will be needed to expand and modify this proposal, with the ultimate goal of creating privacy-enhancing infrastructure that can be used in regulated environments.


