
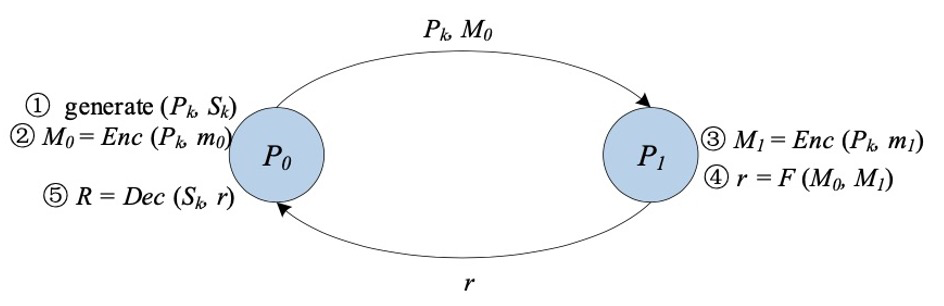
聯邦學習框架淺析
【前言】
【前言】
▲ 聯邦學習問題回顧前文提及,於2016年,Google提出了用於訓練輸入法模型的新型方式,稱為「聯邦學習」。隨著時間的推移,聯邦學習不再是單純解決Google輸入法模型的一種解決方案,進而形成了一種新型的學習模式。聯邦學習解決的問題通常被稱為TMMPP--Training Machine Learning Models over multiple data sources with Privacy,即在保證多方參與者的數據不洩露的情況下,共同完成預定模型的訓練。在聯邦學習解決的TMMPP問題中,包含了n個數據方(Data Controller){D1,D2,...Dn},其中,每個數據方對應擁有著n個數據{P1,P2,... Pn}。從聯邦學習的訓練模式來看,在選定好需要進行訓練的聯邦學習算法後,需為聯邦學習提供相應的輸入,最終得到訓練後的輸出。
聯邦學習的輸入(Input): 每個數據方將Pi其擁有的原始數據Di作為聯合建模的輸入,輸入進聯邦學習的進程中。
聯邦學習的輸出(Output):聯合所有參與方的數據,聯邦訓練出全局模型M (在訓練過程中不將任何數據方的原始數據的任何信息透露給其他實體)。
▲ 聯邦學習所遇挑戰
聯邦學習技術還在持續的完善中。在發展的過程中,聯邦學習會遇到三大挑戰,他們分別分別是統計挑戰、效率挑戰、安全挑戰。
【統計挑戰】統計挑戰是在聯邦學習執行過程中,因為不同用戶數據的分佈或者數據量的差異造成的挑戰;
a)非獨立同分佈數據(Non-IID data),即不同用戶數據分佈不獨立,有明顯的分佈差別,比如甲方擁有的是中國北方的水稻種植數據,而乙方擁有的是中國南方水稻種植數據,由於緯度,氣候,人文等影響,雙方的數據是不服從於同分佈的;
b)非平衡數據(Unbalanced data),即用戶的數據量有明顯的差異,比如巨頭企業掌握著近千萬的數據量,而小公司僅掌握數萬條的數據,兩者合作,小公司的數據對巨頭企業的影響微乎其微,也難以在模型訓練中做出貢獻。
【效率挑戰】效率挑戰指的是在聯邦學習中各個節點本地計算與通信的消耗造成的挑戰;
a)通信開銷,即用戶(參與方)節點之間的通信,通常指的是在限定帶寬的前提下,各個用戶之間傳輸的數據量的大小,數據量越大,則通信損耗越高;
b)計算複雜度,即基於底層加密協議的計算複雜度,通常指底層加密協議計算的時間複雜度,算法計算邏輯越複雜,消耗時間越多。
【安全挑戰】安全挑戰指的是,在聯邦學習過程中,不同的用戶使用不同的攻擊手段造成信息破解、下毒等挑戰;
a)半誠實模型,即各用戶誠實的執行聯邦學習中的所有協議,但是會利用獲取信息嘗試分析並回推他人數據;
b)惡意模型,即存在客戶不會嚴格遵守節點之間的協議,並可能對原始數據或者中間數據進行下毒以破壞聯邦學習進程。
【聯邦學習常用框架】
面對以上三大挑戰,學術界進行針對性的研究,提出了許多有效的、專用的聯邦學習框架來優化聯邦學習訓練過程。下文我們將對這些框架進行簡單介紹。
聯邦學習1.0 – 傳統聯邦學習(Federated Learning)
首先,我們重新闡述一下聯邦學習的概念與原理:存在若干參與方與協作方共同執行聯邦學習任務,參與方(即數據擁有方)通過預置好的聯邦學習算法,生成類似於梯度的中間數據,交由協調方進行進一步的處理,隨後返還給各參與方,為下一輪的訓練做準備。
周而復始,聯邦學習任務完成。整個任務中,參與方的本地數據在各個FL框架中並沒有參與交換,但協調方和參與方之間傳輸的參數(比如梯度)可能會洩漏敏感信息。
為了保護數據擁有方的本地數據不被洩露,並在訓練過程中保護中間數據的隱私,在FL的框架中應用了一些隱私技術,在參與方與協調方交互時私下交換參數。進一步,從FL 框架中使用的隱私保護機制來看,將FL框架分為:
1)非加密的聯邦學習框架(即未對任何信息加密);
2)基於差分隱私的聯邦學習框架(使用差分隱私的方式對信息進行混淆加密);
3)基於安全多方計算的的聯邦學習框架(使用安全多方計算的方法對信息進行加密) ;
▲ 非加密的聯邦學習框架
許多FL框架側重於提高效率或解決統計異質性的挑戰,而忽略了交換明文參數所帶來的潛在風險。
2015年,由Nishio等人提出的用於機器學習的移動邊緣計算框架FedCS[3],在異構數據屬主的設置的基礎上,可以快速並高效地執行FL。
2017年,由Smith等人提出了一個名為MOCHA[2]的系統感知優化框架,該框架將FL與多任務學習相結合,通過多任務學習的方式來處理統計挑戰中的非同分佈數據與數據量差異導致的各種挑戰。
同年,樑等人提出了LG-FEDAVG[4]結合局部表示學習(local representation learning)。他們表明,局部模型可以更好地處理異構數據,並有效地學習公平的表示,混淆受保護的屬性。
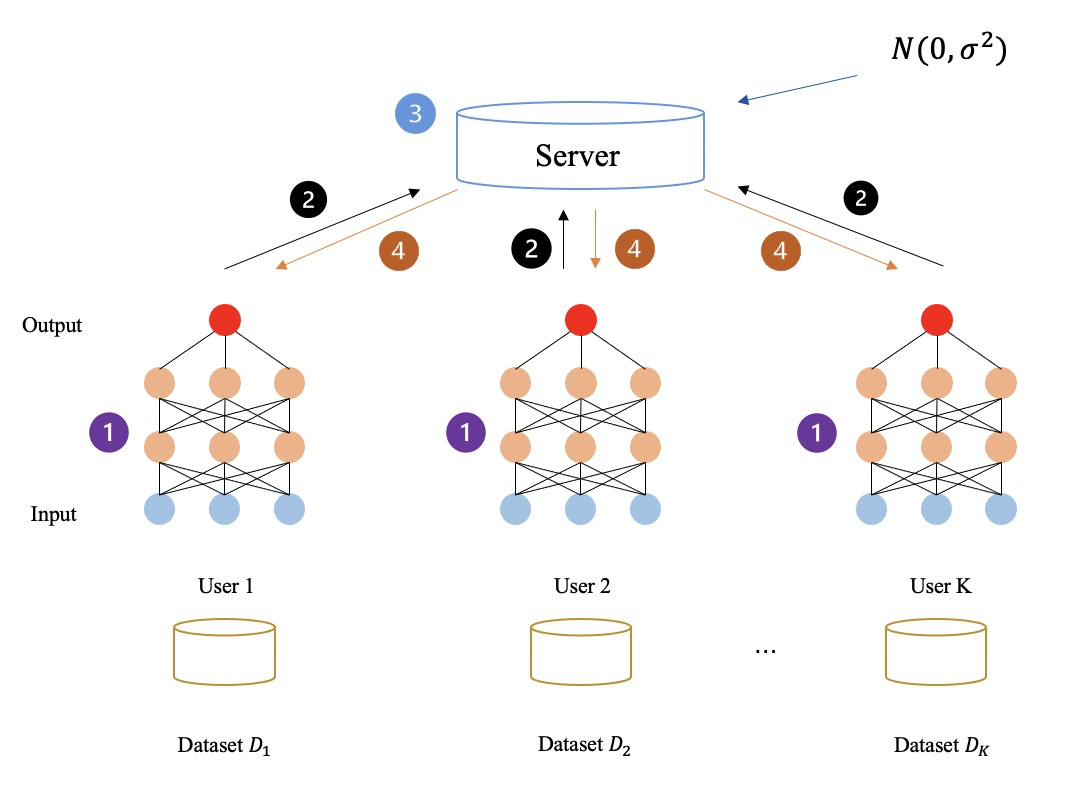
下圖所示:完全未加密任何中間數據的聯邦學習流程,所有的中間數據(如梯度)全是明文傳輸與計算。通過以上方式,參與方最終共同學習,得到聯邦學習模型。
▲ 基於差分隱私的聯邦學習框架
差分隱私(DP) 是一種隱私技術[5-7],具有很強的信息理論保證,可以在數據[8-10]中增加噪聲。滿足DP 的數據集可以抵抗對私有數據的任何分析,換句話說,所獲得的數據敵手對於在同一數據集中推測其他數據幾乎是無用的。通過在原始數據或模型參數中添加隨機噪聲,DP 為單個記錄提供統計隱私保證,從而使數據無法恢復以保護數據屬主的隱私。
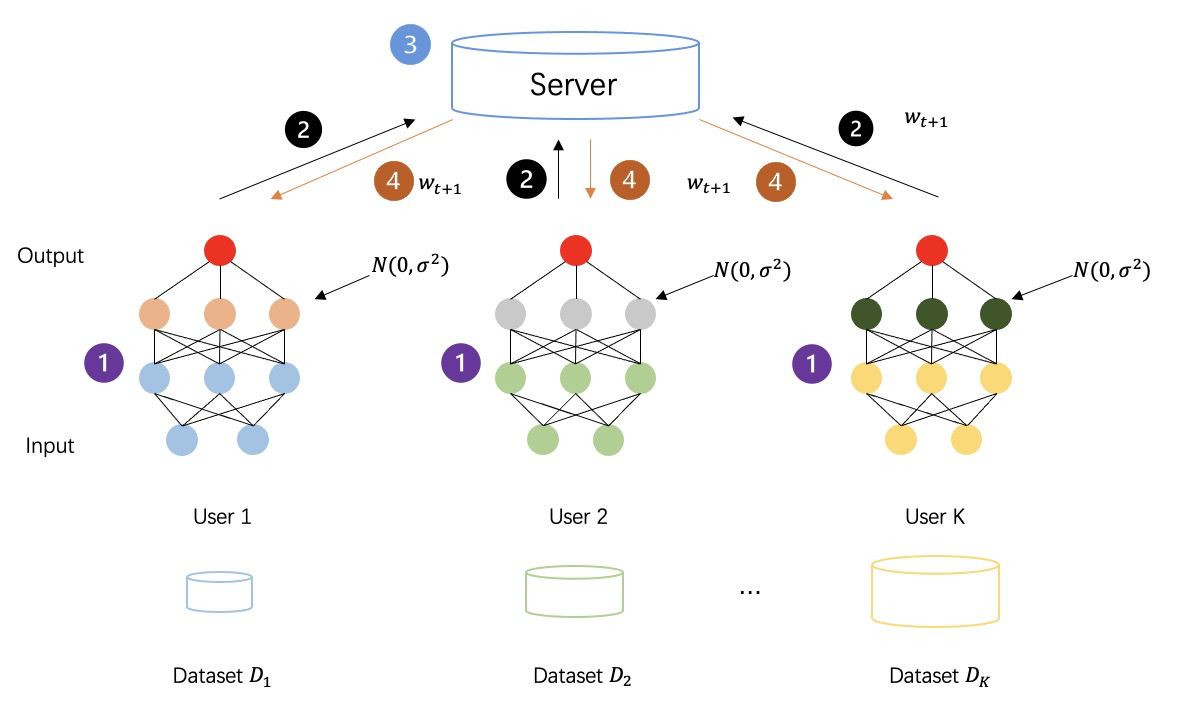
下圖所示:採取差分隱私對中間數據進行加密後的聯邦學習流程,各方生成的中間數據不再是明文傳輸計算,而是添加過噪聲的隱私數據,以此來進一步增強訓練過程的安全性。
▲ 基於安全多方計算的聯邦學習框架
在FL框架中,同態加密(HE)和安全多方計算(MPC)等方法得到了廣泛的應用,但它們只向參與方與協調方揭示了計算結果,過程中並沒有透露任何除計算結果外的額外的信息。
實際上,HE應用於FL框架的方式與應用於安全多方學習(MPL)框架(一種FL衍生出的框架,下文會詳細說明MPL框架)的方式類似,只是細節上略有不同。在FL框架中,HE用於保護參與方和協調方之間交互的模型參數(如梯度)的隱私,而不是像MPL框架中應用的HE那樣直接保護參與方之間交互的數據。 [1]在FL模型中應用加法同態(AHE)來保護梯度的隱私,以提供針對半誠信中心化協調方的安全性。
MPC 涉及多個方面,並保留了原有的準確性,具有很高的安全性保證。 MPC保證了每一方除了結果之外什麼都不知道。因此MPC可以應用於FL 模型中,用於安全聚合併保護本地模型。在基於MPC 的FL 框架中,集中式的協調方不能獲得任何本地信息和本地更新,而是在每一輪協作獲得聚合結果。然而,如果在FL框架中應用MPC 技術將會產生大量額外的通信和計算成本。
迄今為止,秘密共享(SS )是在FL 框架中應用最廣泛的MPC基礎協議,特別是Shamir 的SS[24]。
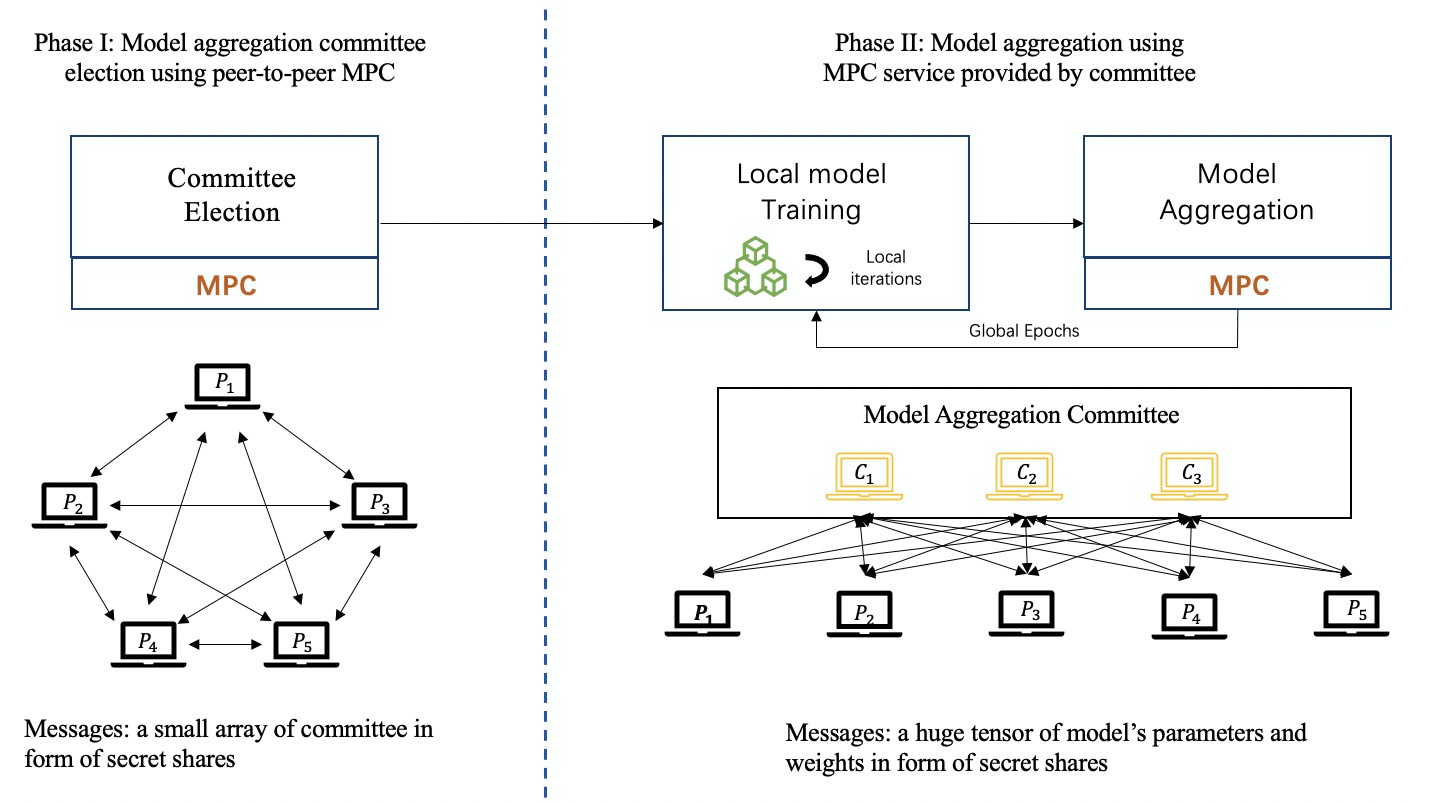
下圖所示:基於MPC的聯邦學習訓練流程,會由參與方公平的選舉出一組委員會成員作為協調方,通過執行MPC技術來協作完成模型聚合的任務。
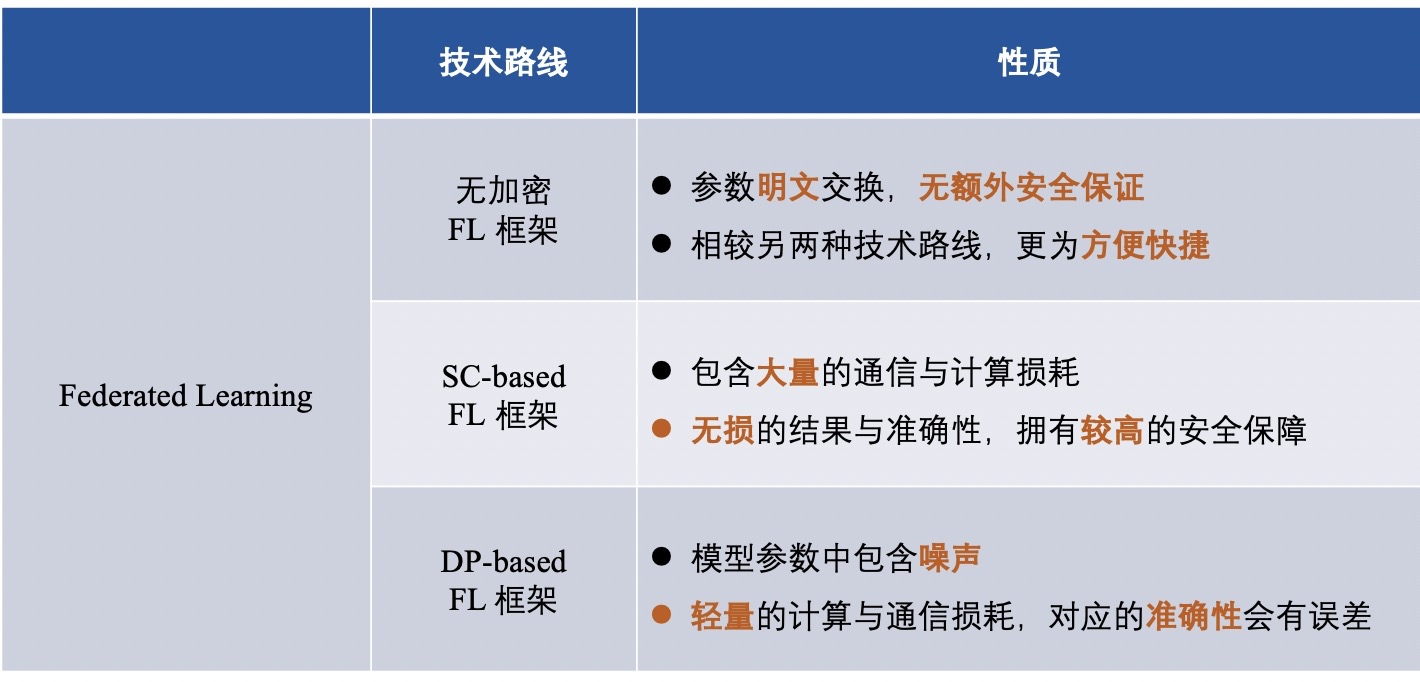
介紹完三種FL框架後,我們總結不同技術路線的框架區別,大體如下:
聯邦學習2.0 -- 安全多方學習(Secure Multi-party Learning)
上文我們提到到「安全多方學習」,這是基於聯邦學習衍生出的一個術語,簡單來說就是:沒有第三方協作方的聯邦學習,被稱之為安全多方學習(MPL),與先前所介紹的FL區分開來。換言之,在聯邦學習的基礎上,安全多方學習剔除了傳統聯邦學習模式中的協調方,並弱化了協調方的能力,將原本的星形網絡替換成點對點網絡並使得所有參與方的地位相同。
MPL的框架大體分為四類,包括:
1)基於同態加密(HE)的MPL 框架;
2)基於混淆電路(GC)的MPL 框架;
3)基於秘密共享(SS)的MPL 框架;
4)基於混合協議的MPL 框架;
簡單來說,不同的MPL框架即為:使用了不同的密碼學協議來保障中間數據安全的框架。 MPL的流程與FL大體類似,我們一起看一下使用過的四種密碼學協議:
▲ 同態加密(HE)
同態加密(HE)是一種加密形式,我們可以在不解密,不知道密鑰的前提下,直接對密文執行特定的代數操作。然後,它生成一個加密結果,其解密結果與在明文上執行的相同操作的結果完全相同。
HE 可以分為「三種類型」:1)部分同態加密(PHE),PHE只允許無限次的一種操作(加法或乘法);2)-3)有限同態加密(SWHE)與全同態加密(FHE),為了在密文中同時進行加法和乘法SWHE和FHE 。 SWHE 可以在有限次數內執行某些類型的操作,而FHE 可以在無限次數處理所有操作。 FHE 的計算複雜度比SWHE 和PHE 要昂貴得多。
▲ 混淆電路(GC)
混淆電路[11][12](GC),又稱姚氏(Yao's) 混淆電路,是由姚期智院士提出的一種安全的兩方計算的底層技術。 GC提供了一個交互式協議,讓兩方(一個混淆者garbler和一個評估者evaluator)對一個任意函數進行無意識的評估,這個函數通常表示為一個布爾電路。
在經典GC 的構造中主要包括三個階段:加密、傳輸、評估。
首先,對於電路中的每一條線,混淆者生成兩個隨機字符串作為標籤,分別代表該線可能的兩個位值“0”和“1”。對於電路中的每一個門,混淆者都會創建一個真值表。真值表的每個輸出都是用與其輸入相對應的兩個標籤進行加密。這是由混淆者選擇一個密鑰推導函數,利用這兩個標籤生成對稱密鑰。
然後,混淆者對真值表的行進行換行。在混淆階段結束後,混淆者將混淆後的表以及與其輸入為對應的輸入線標籤傳送給評估者。
此外,評估者通過不經意傳輸(Oblivious Transfer[13,14,15])安全地獲取其輸入對應的標籤。有了混淆表和輸入線的標籤,評估者負責對混淆表進行反复解密,直至得到函數的最終結果。
▲ 秘密共享(SS)
GMW協議是第一個安全的多方計算協議,允許任意數量的一方安全地計算一個可以表示為布爾電路或算術電路的函數。以布爾電路為例,所有各方使用基於XOR的SS方案共享輸入,各方交互計算結果,逐門計算。基於GMW的協議不需要對真值表進行混淆,只需要進行XOR和AND運算進行計算,所以不需要進行對稱的加解密操作。此外,基於GMW的協議允許預先計算所有的加密操作,但在在線階段需要多方進行多輪交互。因此,GMW在低延遲網絡中取得了良好的性能。
BGW協議是3方以上的算術電路安全多方計算的協議。該協議的總體結構與GMW類似。一般來說,BGW 可以用來計算任何算術電路。與GMW協議類似,對於電路中的加法門,計算是可以在本地進行的,而對於乘法門,各方需要交互。但是,GMW和BGW在交互形式上有所不同。 BGW不是使用OT來進行各方之間的通信,而是依靠線性SS(如Shamir 的SS)來支持乘法運算。但BGW 依靠的是誠實多數制(honest-majority)。 BGW 協議可以對抗除t
SPDZ是Damgard 等人提出的一種不誠實多數制計算協議,它能夠支持兩方以上的計算算術電路。它分為離線階段和在線階段。 SPDZ的優勢在於昂貴的公鑰密碼計算可以在離線階段完成,而在線階段則純粹使用廉價的、信息理論上安全的基元。 SWHE用於在離線階段執行constant-round的安全乘法。 SPDZ的在線階段是linear-round ,遵循GMW範式,在有限域上使用秘密共享來確保安全。 SPDZ最多可以對抗惡意敵手的t<=n個腐壞方,其中t為敵手數量,n為計算方數。
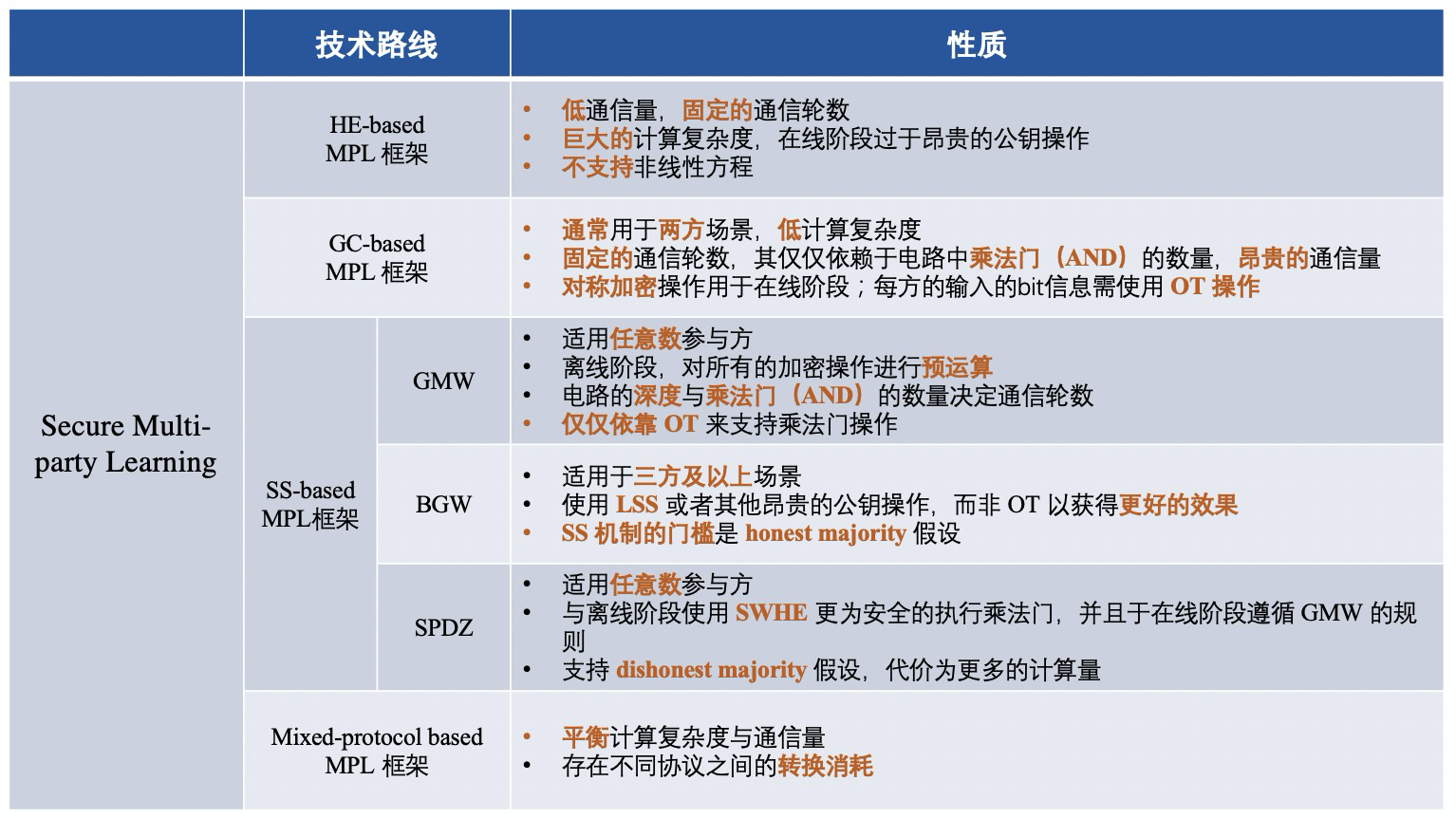
將集中密碼學協議進行階段性總結,不同技術路線對應的框架區別大體如下:
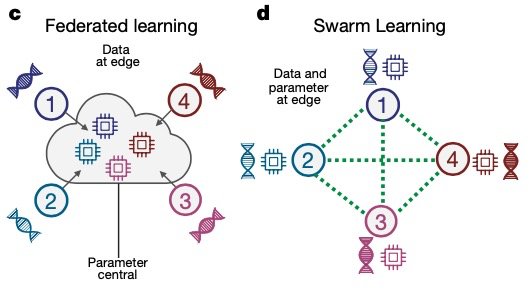
聯邦學習3.0 -- 群學習(Swarm Learning)
2021年,波恩大學的Joachim Schultze 和他的合作夥伴提出了一種名為Swarm Learning(群學習)的「去中心化機器學習系統」,這是基於MPL進一步的衍化升級,它取代了當前跨機構醫學研究中集中數據共享的方式。 Swarm Learning 通過Swarm 網絡共享參數,再在各個參與方的本地數據上獨立構建模型,並利用區塊鏈技術對試圖破壞Swarm 網絡的不誠實參與者採取強有力的措施。
相較於FL與MPL, Swarm Learning將區塊鏈的技術引入到聯邦學習的訓練過程中,很好地將區塊鏈取代了公信第三方,起到訓練協同的作用。
【總結與展望】▲ 聯邦學習技術路線比較
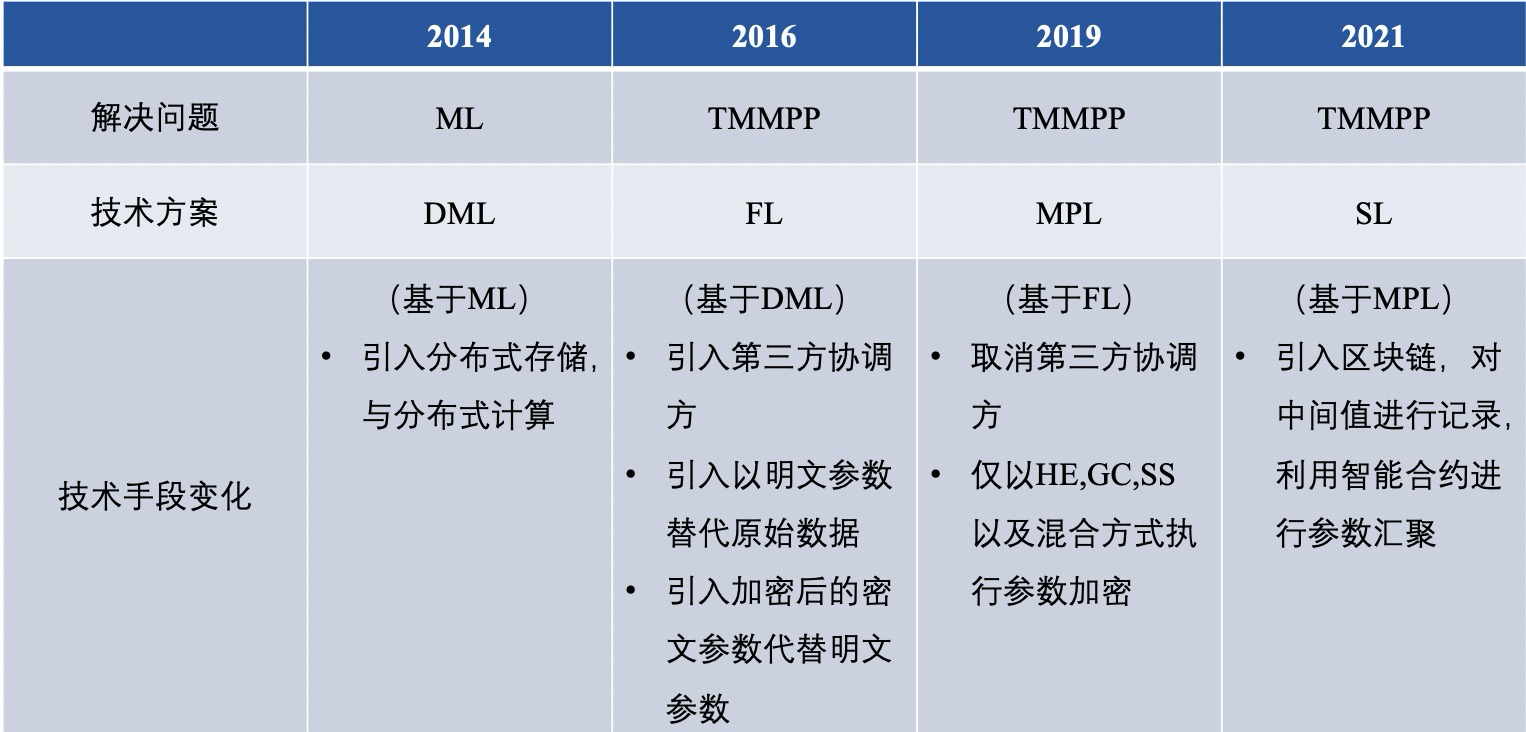
縱觀聯邦學習的前世今生,其已經擁有了多種解決問題的技術路線,經總結,分佈式機器學習(DML),聯邦學習(FL),安全多方學習(MPL),群學習(SL)的差異大體如下:
這其中,我們將傳統的FL與MPL進行更深層次的對比,體現在以下六點:
1) 隱私保護
MPC 框架中使用的MPC 協議為雙方提供了很高的安全性保證。然而,非加密FL 框架在數據屬主和服務器之間交換模型參數是明文的,敏感信息也可能被洩露;
2) 通信方式
在MPL 中,數據屬主之間的通信通常是在沒有可信第三方的情況下以對等的形式進行的,而FL 通常是以具有集中式服務器的Client-Server的形式進行的。換句話說,MPL中的每個數據屬主在狀態上是相等的,而FL 中的數據屬主和集中式服務器是不對等的;
3) 通信開銷
對於FL,由於數據屬主之間的通信可以由一個中心化服務器來協調,通信開銷比MPL 的點對點形式更小,特別是當數據屬主的數量非常大時;
4) 數據格式
目前,在MPL 的解決方案中,不考慮非IID 設置。然而,在FL的解決方案中,由於每個數據屬主都在本地訓練模型,因此更容易適應非IID 設置;
5) 訓練模型的準確性
在MPL 中,在全局模型中通常沒有精度損失。但如果FL 利用DP 保護隱私,全局模型通常會有一定的準確性損失;
6) 應用場景
結合上述分析,可以發現MPL 更適合於安全性和準確性較高的場景,而FL 更適合於性能要求較高的場景,用於更多的數據擁有方。
▲ 聯邦學習框架多方比較
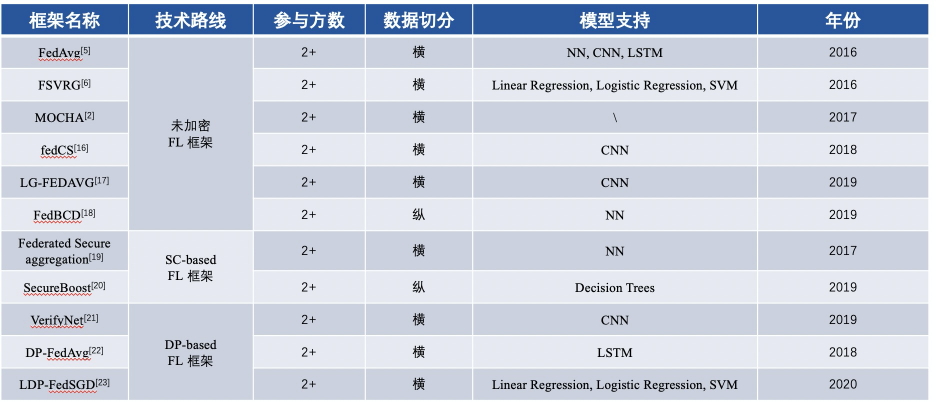
自2016年FL基礎性框架的內容對比
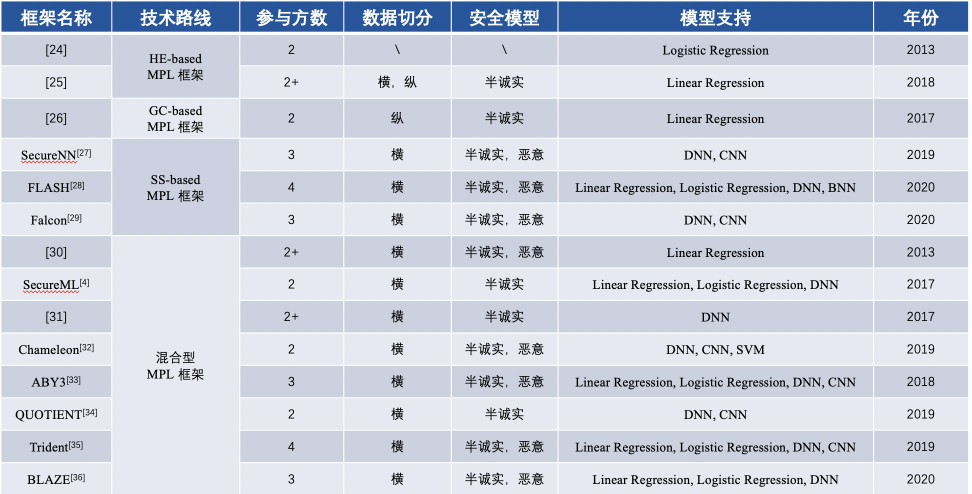
基於FL的MPL基礎框架的內容對比
隨著聯邦學習技術的不斷發展,針對不同挑戰的聯邦學習平台不斷湧現,但仍未達到成熟的階段。目前,在學術界中,聯邦學習平台主要解決的問題是非平衡與非同分佈的數據問題,而工業界更多的把眼光放在了密碼學協議上來解決聯邦學習的安全問題。
兩邊齊頭並進,將現有的很多機器學習算法實現了聯邦化,但仍不成熟,並未達到可以落地投產的階段。近幾年,聯邦學習框架的研究與落地仍處於初級階段,需要持續不斷的努力和推進。
正文
參考文獻
參考文獻
[1] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[2] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[3] D. Demmler, T. Schneider, and M. Zohner, “Aby-a framework for efficient mixed-protocol secure two-party computation.” in Proceedings of The Network and Distributed System Security Symposium, 2015.
[4] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy- preserving machine learning,” in Proceedings of 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017, pp. 19–38.
[5] H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas, “Feder- ated learning of deep networks using model averaging,” CoRR, vol. abs/1602.05629, 2016.
[6] J. Konecˇny`, H. B. McMahan, D. Ramage, and P. Richta ́rik, “Federated optimization: Distributed machine learning for on-device intelligence,” arXiv preprint arXiv:1610.02527, 2016.
[7] J. Konecˇny`, H. B. McMahan, F. X. Yu, P. Richta ́rik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communica- tion efficiency,” arXiv preprint arXiv:1610.05492, 2016.
[8] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentral- ized data,” in Proceedings of Artificial Intelligence and Statistics, 2017, pp. 1273–1282.
[9] A. C.-C. Yao, “How to generate and exchange secrets,” in Proceedings of the 27th Annual Symposium on Foundations of Computer Science (sfcs 1986). IEEE, 1986, pp. 162–167.
[10] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Proceedings of Advances in Neural Information Processing Systems, 2017, pp. 4424–4434.
[11] R. Fakoor, F. Ladhak, A. Nazi, and M. Huber, “Using deep learning to enhance cancer diagnosis and classification,” in Proceedings of the international conference on machine learning, vol. 28. ACM New York, USA, 2013.
[12] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary convolutional neural networks,” in Proceedings of European conference on computer vision. Springer, 2016, pp. 525–542.
[13] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823.
[14] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[15] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[16] T.NishioandR.Yonetani,“Clientselectionforfederatedlearningwith heterogeneous resources in mobile edge,” in Proceedings of 2019 IEEE International Conference on Communications (ICC). IEEE, 2019, pp. 1–7.
[17] P. P. Liang, T. Liu, L. Ziyin, R. Salakhutdinov, and L.-P. Morency, “Think locally, act globally: Federated learning with local and global representations,” arXiv preprint arXiv:2001.01523, 2020.
[18] Y. Liu, Y. Kang, X. Zhang, L. Li, Y. Cheng, T. Chen, M. Hong, and Q. Yang, “A communication efficient vertical federated learning framework,” arXiv preprint arXiv:1912.11187, 2019.
[19] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggre- gation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191.
[20] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, and Q. Yang, “Se- cureboost: A lossless federated learning framework,” arXiv preprint arXiv:1901.08755, 2019.
[21] G. Xu, H. Li, S. Liu, K. Yang, and X. Lin, “Verifynet: Secure and verifiable federated learning,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 911–926, 2019.
[22] H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang, “Learn- ing differentially private recurrent language models,” arXiv preprint arXiv:1710.06963, 2017.
[23] Y. Zhao, J. Zhao, M. Yang, T. Wang, N. Wang, L. Lyu, D. Niyato, and K. Y. Lam, “Local differential privacy based federated learning for internet of things,” arXiv preprint arXiv:2004.08856, 2020.
[24] M. Hastings, B. Hemenway, D. Noble, and S. Zdancewic, “Sok: General purpose compilers for secure multi-party computation,” in Proceedings of 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 1220–1237.
[25] I. Giacomelli, S. Jha, M. Joye, C. D. Page, and K. Yoon, “Privacy-
preserving ridge regression with only linearly-homomorphic encryp- tion,” in Proceedings of 2018 International Conference on Applied Cryptography and Network Security. Springer, 2018, pp. 243–261.
[26] A. Gasco ́n, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, and D. Evans, “Privacy-preserving distributed linear regression on high- dimensional data,” Proceedings on Privacy Enhancing Technologies, vol. 2017, no. 4, pp. 345–364, 2017.
[27] S. Wagh, D. Gupta, and N. Chandran, “Securenn: 3-party secure computation for neural network training,” Proceedings on Privacy Enhancing Technologies, vol. 2019, no. 3, pp. 26–49, 2019.
[28] M. Byali, H. Chaudhari, A. Patra, and A. Suresh, “Flash: fast and robust framework for privacy-preserving machine learning,” Proceedings on Privacy Enhancing Technologies, vol. 2020, no. 2, pp. 459–480, 2020.
[29] S. Wagh, S. Tople, F. Benhamouda, E. Kushilevitz, P. Mittal, and T. Rabin, “Falcon: Honest-majority maliciously secure framework for private deep learning,” arXiv preprint arXiv:2004.02229, 2020.
[30] V. Nikolaenko, U. Weinsberg, S. Ioannidis, M. Joye, D. Boneh, and N. Taft, “Privacy-preserving ridge regression on hundreds of millions of records,” pp. 334–348, 2013.
[31] M. Chase, R. Gilad-Bachrach, K. Laine, K. E. Lauter, and P. Rindal, “Private collaborative neural network learning.” IACR Cryptol. ePrint Arch., vol. 2017, p. 762, 2017.
[32] M. S. Riazi, C. Weinert, O. Tkachenko, E. M. Songhori, T. Schneider, and F. Koushanfar, “Chameleon: A hybrid secure computation frame- work for machine learning applications,” in Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 2018, pp. 707–721.
[33] P. Mohassel and P. Rindal, “Aby3: A mixed protocol framework for machine learning,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018, pp. 35– 52.
[34] N. Agrawal, A. Shahin Shamsabadi, M. J. Kusner, and A. Gasco ́n, “Quotient: two-party secure neural network training and prediction,” in Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019, pp. 1231–1247.
[35] R. Rachuri and A. Suresh, “Trident: Efficient 4pc framework for pri- vacy preserving machine learning,” arXiv preprint arXiv:1912.02631, 2019.
[36] A. Patra and A. Suresh, “Blaze: Blazing fast privacy-preserving ma- chine learning,” arXiv preprint arXiv:2005.09042, 2020.
[37] Song L, Wu H, Ruan W, et al. SoK: Training machine learning models over multiple sources with privacy preservation[J]. arXiv preprint arXiv:2012.03386, 2020.


