
LUCIDA:如何利用多因子策略构建强大的加密资产投资组合(因子有效性检验篇)
Lời nói đầu
Tiếp nối cuốn sách trước, chúng tôi đã xuất bản hai bài viết trong loạt bài về Xây dựng danh mục tài sản tiền điện tử mạnh mẽ bằng cách sử dụng mô hình đa yếu tố:Cơ sở lý thuyết、Tiền xử lý dữ liệu
Đây là bài viết thứ ba: kiểm tra tính hợp lệ của yếu tố.
Sau khi xác định giá trị nhân tố cụ thể, trước tiên cần tiến hành kiểm định độ giá trị các nhân tố và sàng lọc các nhân tố đáp ứng yêu cầu về ý nghĩa, tính ổn định, tính đơn điệu và tỷ lệ hoàn vốn; việc kiểm định tính giá trị của nhân tố được thực hiện bằng cách phân tích mối quan hệ giữa các nhân tố. giá trị của kỳ hiện tại và mối quan hệ tỷ suất lợi nhuận kỳ vọng để xác định tính hợp lệ của các yếu tố. Chủ yếu có 3 phương pháp cổ điển:
Phương pháp IC/IR: Giá trị IC/IR là hệ số tương quan giữa giá trị yếu tố và lợi nhuận kỳ vọng, hệ số càng lớn thì hiệu quả hoạt động càng tốt.
Giá trị T (phương pháp hồi quy): Giá trị T phản ánh tầm quan trọng của hệ số sau khi hồi quy tuyến tính lợi nhuận của kỳ tiếp theo đối với giá trị yếu tố của kỳ hiện tại. Bằng cách so sánh xem hệ số hồi quy có vượt qua thử nghiệm t hay không, chúng ta có thể đánh giá sự đóng góp của giá trị yếu tố của kỳ hiện tại với lợi nhuận của kỳ tiếp theo. Thường được sử dụng trong các mô hình hồi quy đa biến (tức là đa yếu tố).
Phương pháp kiểm tra ngược phân cấp: Phương pháp kiểm tra ngược phân cấp phân tầng các mã thông báo dựa trên các giá trị hệ số, sau đó tính toán tỷ lệ hoàn vốn của từng lớp mã thông báo để xác định tính đơn điệu của các yếu tố.
1. Luật IC/IR
(1) Định nghĩa IC/IR
IC: Hệ số thông tin, thể hiện khả năng dự đoán lợi nhuận của Token của yếu tố đó. Giá trị IC của một kỳ nhất định là hệ số tương quan giữa giá trị hệ số của kỳ hiện tại và tỷ suất lợi nhuận của kỳ tiếp theo.
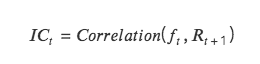

IC càng gần 1 thì mối tương quan dương giữa giá trị yếu tố và tỷ suất lợi nhuận của kỳ tiếp theo càng mạnh. IC= 1 có nghĩa là lựa chọn tiền tệ của yếu tố đó chính xác 100%, tương ứng với mã thông báo có điểm xếp hạng cao nhất. Mã thông báo đã chọn sẽ được sử dụng trong chu kỳ điều chỉnh vị trí tiếp theo. , mức tăng lớn nhất;
IC càng gần -1 thì mối tương quan nghịch giữa giá trị hệ số và tỷ suất lợi nhuận trong kỳ tiếp theo càng mạnh, nếu IC=-1 nghĩa là token có thứ hạng cao nhất sẽ có mức giảm lớn nhất trong kỳ tiếp theo. chu kỳ tái cân bằng, đó là một sự đảo ngược hoàn toàn chỉ số;
Nếu IC gần bằng 0 nghĩa là khả năng dự đoán của yếu tố đó cực kỳ yếu, cho thấy yếu tố đó không có khả năng dự đoán về token.
IR: tỷ số thông tin, biểu thị khả năng của các yếu tố có được Alpha ổn định. IR là IC trung bình của tất cả các thời kỳ chia cho độ lệch chuẩn IC của tất cả các thời kỳ.
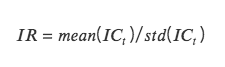
Khi giá trị tuyệt đối của IC lớn hơn 0,05 (0,02) thì khả năng lựa chọn cổ phiếu của nhân tố này mạnh. Khi IR lớn hơn 0,5, yếu tố này có khả năng mạnh mẽ để thu được lợi nhuận vượt trội một cách ổn định.
(2) Cách tính IC
IC thông thường (tương quan Pearson): Tính hệ số tương quan Pearson, hệ số tương quan cổ điển nhất. Tuy nhiên, có nhiều giả định trong phương pháp tính toán này: dữ liệu liên tục, có phân phối chuẩn, hai biến thỏa mãn mối quan hệ tuyến tính, v.v.
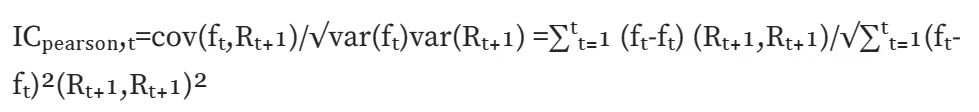
Xếp hạng IC (Hệ số tương quan xếp hạng của Spearman): Tính hệ số tương quan xếp hạng của Spearman, trước tiên sắp xếp hai biến, sau đó tính hệ số tương quan Pearson dựa trên kết quả được sắp xếp.Hệ số tương quan xếp hạng của Spearman đánh giá mối quan hệ đơn điệu giữa hai biến và ít bị ảnh hưởng bởi các ngoại lệ dữ liệu vì nó được chuyển đổi thành các giá trị có thứ tự;Hệ số tương quan Pearson đánh giá mối quan hệ tuyến tính giữa hai biến, nó không chỉ có những điều kiện tiên quyết nhất định đối với dữ liệu gốc mà còn bị ảnh hưởng rất nhiều bởi các dữ liệu ngoại lệ. Trong tính toán thực tế, việc tìm hạng IC sẽ phù hợp hơn.
(3) Triển khai mã phương pháp IC/IR
Tạo danh sách các giá trị ngày và giờ duy nhất theo thứ tự ngày và giờ tăng dần - ghi lại ngày tái cân bằng def choosedate(dateList, Cycle)
class TestAlpha(object):
def __init__(self, ini_data):
self.ini_data = ini_data
def chooseDate(self, cycle, start_date, end_date):
'''
cycle: day, month, quarter, year
df: khung dữ liệu gốc df, xử lý cột ngày tháng
'''
chooseDate = []
dateList = sorted(self.ini_data[self.ini_data['date'].between(start_date, end_date)]['date'].drop_duplicates().values)
dateList = pd.to_datetime(dateList)
for i in range(len(dateList)-1):
if getattr(dateList[i], cycle) != getattr(dateList[i + 1 ], cycle):
chooseDate.append(dateList[i])
chooseDate.append(dateList[-1 ])
chooseDate = [date.strftime('%Y-%m-%d') for date in chooseDate]
return chooseDate
def ICIR(self, chooseDate, factor):
# 1. Đầu tiên hiển thị IC của từng ngày điều chỉnh vị thế, tức là ICt
testIC = pd.DataFrame(index=chooseDate, columns=['normalIC','rankIC'])
dfFactor = self.ini_data[self.ini_data['date'].isin(chooseDate)][['date','name','price', factor]]
for i in range(len(chooseDate)-1):
# ( 1) normalIC
X = dfFactor[dfFactor['date'] == chooseDate[i]][['date','name','price', factor]].rename(columns={'price':'close 0'})
Y = pd.merge(X, dfFactor[dfFactor['date'] == chooseDate[i+ 1 ]][['date','name','price']], on=['name']).rename(columns={'price':'close 1'})
Y['returnM'] = (Y['close 1'] - Y['close 0']) / Y['close 0']
Yt = np.array(Y['returnM'])
Xt = np.array(Y[factor])
Y_mean = Y['returnM'].mean()
X_mean = Y[factor].mean()
num = np.sum((Xt-X_mean)*(Yt-Y_mean))
den = np.sqrt(np.sum((Xt-X_mean)** 2)*np.sum((Yt-Y_mean)** 2))
normalIC = num / den # pearson correlation
# ( 2) rankIC
Yr = Y['returnM'].rank()
Xr = Y[factor].rank()
rankIC = Yr.corr(Xr)
testIC.iloc[i] = normalIC, rankIC
testIC =testIC[:-1 ]
# 2. Dựa vào ICt tìm [IC_Mean, IC_Std,IR,IC<0 tỷ lệ--hướng hệ số,-IC->0,05 tỷ lệ]
'''
ICmean: |IC|>0.05,Các yếu tố có khả năng lựa chọn đồng tiền mạnh mẽ và giá trị yếu tố có mối tương quan cao với tỷ suất lợi nhuận của kỳ tiếp theo. -IC-<0.05,Khả năng lựa chọn tiền tệ của yếu tố yếu và mối tương quan giữa giá trị yếu tố và tỷ suất lợi nhuận của kỳ tiếp theo thấp.
IR: |IR|>0.5,Khả năng lựa chọn tiền tệ của yếu tố rất mạnh và giá trị IC tương đối ổn định. -IR-<0.5,Giá trị IR quá nhỏ và hệ số không hiệu quả lắm. Nếu nó gần bằng 0 thì về cơ bản nó không hợp lệ.
IClZero (IC nhỏ hơn 0): IC<0 chiếm gần một nửa -> hệ số trung tính, IC>0 vượt quá một nửa là hệ số âm, tức là khi giá trị hệ số tăng thì tỷ suất hoàn vốn giảm
ICALzpF(IC abs large than zero poin five): |IC|>Tỷ lệ 0,05 ở mức cao, cho thấy hầu hết các yếu tố đều có hiệu quả.
'''
IR = testIC.mean()/testIC.std()
IClZero = testIC[testIC<0 ].count()/testIC.count()
ICALzpF = testIC[abs(testIC)>0.05 ].count()/testIC.count()
combined =pd.concat([testIC.mean(), testIC.std(), IR, IClZero, ICALzpF], axis= 1)
combined.columns = ['ICmean','ICstd','IR','IClZero','ICALzpF']
#3.Biểu đồ tích lũy IC của IC trong thời gian tái cân bằng
print("Test IC Table:")
print(testIC)
print("Result:")
print('normal Skewness:', combined['normalIC'].skew(),'rank Skewness:', combined['rankIC'].skew())
print('normal Skewness:', combined['normalIC'].kurt(),'rank Skewness:', combined['rankIC'].kurt())
return combined, testIC.cumsum().plot()
2. Kiểm định giá trị T (phương pháp hồi quy)
Phương pháp giá trị T cũng kiểm tra mối quan hệ giữa giá trị yếu tố của kỳ hiện tại và tỷ suất lợi nhuận của kỳ tiếp theo, nhưng nó khác với phương pháp ICIR ở chỗ phân tích mối tương quan giữa hai giá trị này. trở lại dưới dạng biến phụ thuộc Y và giá trị hệ số của kỳ hiện tại là biến độc lập X. Đối với hồi quy X, hãy tiến hành kiểm định t trên hệ số hồi quy của giá trị hệ số hồi quy để kiểm tra xem nó có khác biệt đáng kể so với 0 hay không, nghĩa là liệu yếu tố kỳ hiện tại ảnh hưởng đến tỷ suất lợi nhuận của kỳ tiếp theo.
Bản chất của phương pháp này là giải mô hình hồi quy hai biến, công thức cụ thể như sau:
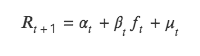

(1) Lý thuyết phương pháp hồi quy

(2) Thực hiện mã phương pháp hồi quy
def regT(self, chooseDate, factor, return_ 24 h):
testT = pd.DataFrame(index=chooseDate, columns=['coef','T'])
for i in range(len(chooseDate)-1):
X = self.ini_data[self.ini_data['date'] == chooseDate[i]][factor].values
Y = self.ini_data[self.ini_data['date'] == chooseDate[i+ 1 ]][return_ 24 h].values
b, intc = np.polyfit(X, Y,1) # độ dốc
ut = Y - (b * X + intc)
# Tìm giá trị t t = (\hat{b} - b) / se(b)
n = len(X)
dof = n - 2 # Bậc tự do
std_b = np.sqrt(np.sum(ut** 2) / dof)
t_stat = b / std_b
testT.iloc[i] = b, t_stat
testT = testT[:-1 ]
testT_mean = testT['T'].abs().mean()
testT L1 96 = len(testT[testT['T'].abs() > 1.96 ]) / len(testT)
print('testT_mean:', testT_mean)
print(Tỷ lệ các giá trị T lớn hơn 1,96:, testT L1 96)
return testT
3. Phương pháp backtesting phân tầng
Sự phân tầng đề cập đến việc phân tầng tất cả các mã thông báo và kiểm tra ngược đề cập đến việc tính toán tỷ lệ hoàn trả của từng lớp kết hợp mã thông báo.
(1) Sự phân tầng
Đầu tiên, lấy giá trị hệ số tương ứng với nhóm mã thông báo và sắp xếp mã thông báo theo giá trị hệ số. Sắp xếp theo thứ tự tăng dần, tức là những phần tử có giá trị hệ số nhỏ hơn sẽ được xếp đầu tiên và các mã thông báo được chia đều theo cách sắp xếp. Giá trị hệ số của mã thông báo lớp 0 là nhỏ nhất và giá trị hệ số của mã thông báo lớp 9 là lớn nhất.
Về mặt lý thuyết, phân chia bằng nhau đề cập đến việc chia đều số lượng mã thông báo, nghĩa là số lượng mã thông báo trong mỗi lớp là như nhau, điều này đạt được với sự trợ giúp của lượng tử. Trong thực tế, tổng số mã thông báo không nhất thiết phải là bội số của số lớp, nghĩa là số lượng mã thông báo trong mỗi lớp không nhất thiết phải bằng nhau.
(2) Kiểm tra lại
Sau khi chia mã thông báo thành 10 nhóm theo thứ tự giá trị hệ số tăng dần, hãy bắt đầu tính tỷ lệ hoàn trả của từng tổ hợp mã thông báo. Bước này coi mã thông báo của mỗi lớp là một danh mục đầu tư (các mã thông báo có trong tổ hợp mã thông báo của mỗi lớp sẽ thay đổi trong các giai đoạn kiểm tra lại khác nhau) và tính toán giá trị tổng thể của danh mục đầu tư.Tỷ suất lợi nhuận kỳ sau. Giá trị ICIR và t phân tích giá trị hệ số hiện tại vàTỷ suất lợi nhuận chung trong kỳ tiếp theo, nhưng việc kiểm tra ngược theo cấp độ yêu cầu phải tính toánTỷ suất lợi nhuận danh mục đầu tư phân tầng cho mỗi ngày giao dịch trong thời gian kiểm tra lại. Vì có nhiều giai đoạn backtesting với nhiều giai đoạn nên cần phải phân tầng và backtesting trong mỗi giai đoạn. Cuối cùng, tỷ lệ hoàn trả mã thông báo của mỗi lớp được nhân tích lũy để tính tỷ lệ hoàn trả tích lũy của tổ hợp mã thông báo.
Lý tưởng nhất, đối với một yếu tố tốt, nhóm 9 có lợi tức đường cong cao nhất và nhóm 0 có lợi tức đường cong thấp nhất.
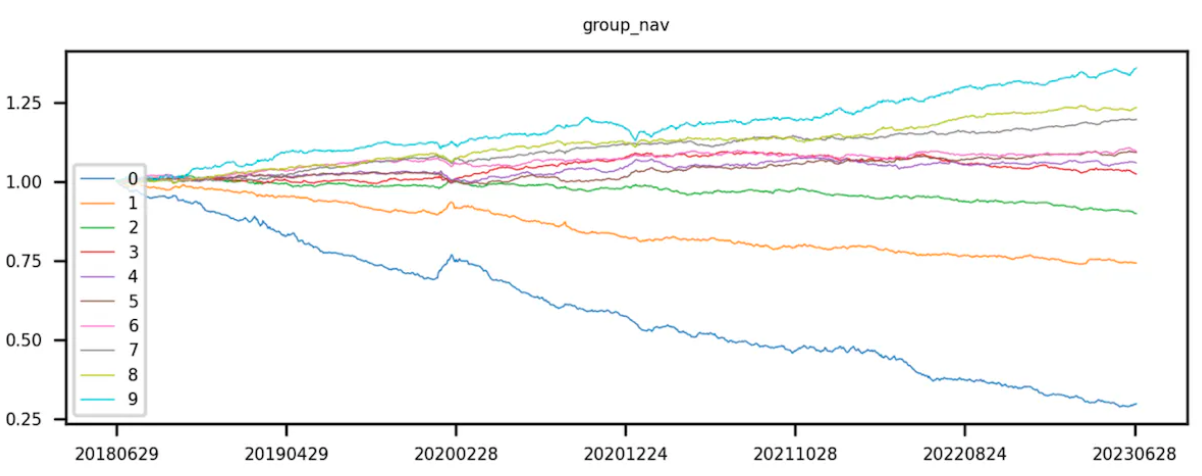
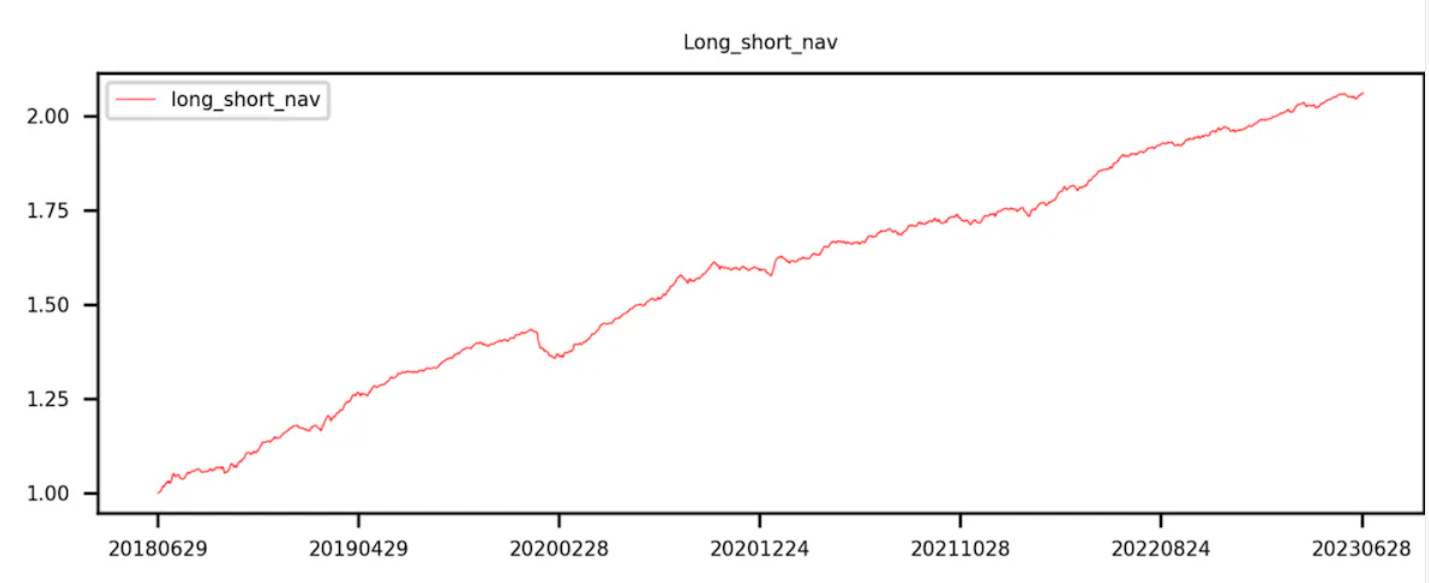
Các đường cong của Nhóm 9 trừ Nhóm 0 (tức là lợi nhuận dài hạn) đang tăng lên đều đặn.
(3) Triển khai mã của phương pháp backtesting phân cấp
def layBackTest(self, chooseDate, factor):
f = {}
returnM = {}
for i in range(len(chooseDate)-1):
df 1 = self.ini_data[self.ini_data['date'] == chooseDate[i]].rename(columns={'price':'close 0'})
Y = pd.merge(df 1, self.ini_data[self.ini_data['date'] == chooseDate[i+ 1 ]][['date','name','price']], left_on=['name'], right_on=['name']).rename(columns={'price':'close 1'})
f[i] = Y[factor]
returnM[i] = Y['close 1'] / Y['close 0'] -1
labels = ['0','1','2','3','4','5','6','7','8','9']
res = pd.DataFrame(index=['0','1','2','3','4','5','6','7','8','9','LongShort'])
res[chooseDate[ 0 ]] = 1
for i in range(len(chooseDate)-1):
dfM = pd.DataFrame({'factor':f[i],'returnM':returnM[i]})
dfM['group'] = pd.qcut(dfM['factor'], 10, labels=labels)
dfGM = dfM.groupby('group').mean()[['returnM']]
dfGM.loc[LongShort] = dfGM.loc[0]- dfGM.loc[9]res[chooseDate[i+ 1 ]] = res[chooseDate[ 0 ]] * ( 1 + dfGM[returnM ]) data = pd.DataFrame({Trả về tích lũy phân cấp:res.iloc[: 10,-1],Group:[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]})
df 3 = data.corr()
print("Correlation Matrix:")
print(df 3)
return res.T.plot(title='Group backtest net worth curve')


