
Interpretation of Bittensor: 400% increase in January, dark horse on the AI+Crypto track
Original author: Knower
Original compilation: Luffy, Foresight News
Related news:

Friends, long time no see. I hope you all have enjoyed some of the recent positive price action in the cryptocurrency space. In order to get a good reward, I decided to write a formal report on the artificial intelligence encryption project Bittensor. Im not an expert on cryptocurrency, so you might think Im not very familiar with artificial intelligence. In reality, however, I spend a lot of my free time doing AI research outside of cryptocurrencies, and have been familiarizing myself with important updates, advancements, and existing infrastructure in the AI space over the past 3-4 months.
Despite some of the tweets being inaccurately worded and lacking in analysis, I want to set the record straight. After reading this article, you will know much more about Bittensor than you expected. This is a somewhat lengthy report, and I didn’t mean to pile on the words. This is largely due to the large number of pictures and screenshots. Please dont enter articles into ChatGPT to get a summary, I invest a lot of time in these and you wont get the whole story that way.
When I was writing this report, a friend (who happens to be a Crypto Twitter KOL) told me, “AI + Cryptocurrency = The Future of Finance.” Please keep this in mind as you read this article.
Is artificial intelligence the final piece of the puzzle for crypto to start taking over the world, or is it just a small step towards our goal? Its up to you to find the answers, Im just offering some food for thought.
Background Information
In Bittensors words, Bittensor is essentially a language for writing numerous decentralized commodity markets or sub-networks located under a unified token system. Its goal is to channel digital market power to societys most important digital commodities. --AI.
Bittensors mission is to build a decentralized network that, through a unique incentive mechanism and advanced sub-network architecture, can compete with previous models that only giant companies like OpenAI can achieve. Bittensor is best imagined as a complete system of interoperable parts, a machine built with the help of blockchain to better facilitate the spread of artificial intelligence capabilities on the chain.
There are two key players that govern the Bittensor network, they are miners and validators. Miners are individuals who submit pre-trained models to the network in exchange for a share of rewards. The validator is responsible for confirming the validity and accuracy of these model outputs and selecting the most accurate output to return to the user. For example, if a Bittensor user requests an AI chatbot to answer a simple question involving derivatives or historical facts, the question will be answered regardless of how many nodes are currently running in the Bittensor network.
The steps for users to interact with the Bittensor network are briefly described as follows: the user sends a query to the validator, the validator propagates it to the miners, the validator then ranks the miner outputs, and the highest-ranked miner output is sent back to the user.
Its all very simple.
Through incentives, models usually provide the best output, and Bittensor creates a positive feedback loop in which miners compete with each other to introduce more refined, accurate, and high-performance models to obtain a larger share of TAO (Bittensor ecological tokens) ) and promote a more positive user experience.
To become a validator, a user must be one of the first 64 holders of TAO and register a UID on any of Bittensors subnetworks (an independent economic marketplace that provides access to various forms of artificial intelligence). For example, subnet 1 focuses on label prediction through text prompts, and subnet 5 focuses on image generation. The two subnetworks may use different models because their tasks are very different and may require different parameters, accuracy, and other specific features.
Another key aspect of Bittensors architecture is the Yuma Consensus mechanism, which is similar to the CPU that distributes the resources available to Bittensor across the entire subnet network. Yuma is described as a hybrid of PoW and PoS, with the added functionality of transmitting and facilitating intelligence off-chain. While Yuma powers the majority of Bittensors network, subnetworks can choose to join or not rely on the Yuma consensus. The specifics are complex and vague, and there are various subnets and corresponding Githubs, so if you just want a general understanding, knowing the top-down approach to Yuma consensus will do the trick.

But what about models?
Contrary to popular belief, Bittensor does not train its own models. This is an extremely expensive process that only larger AI labs or research organizations can afford, and can take a long time. I tried to give an absolute answer as to whether model training is included in Bittensor, but my only findings are not conclusive.

The decentralized training mechanism is a bit difficult to pronounce, but it is not difficult to understand. The Bittensor validator is tasked with playing a continuous game of evaluating miner-generated models on the Falcon Refined Web 6 T-Token unlabeled dataset to evaluate each model based on two criteria: timestamp and loss relative to other models. Miners rate. Loss function is a machine learning term used to describe the difference between predicted and actual values in a certain type of simulation, representing the degree of error or inaccuracy given the input data and model output.
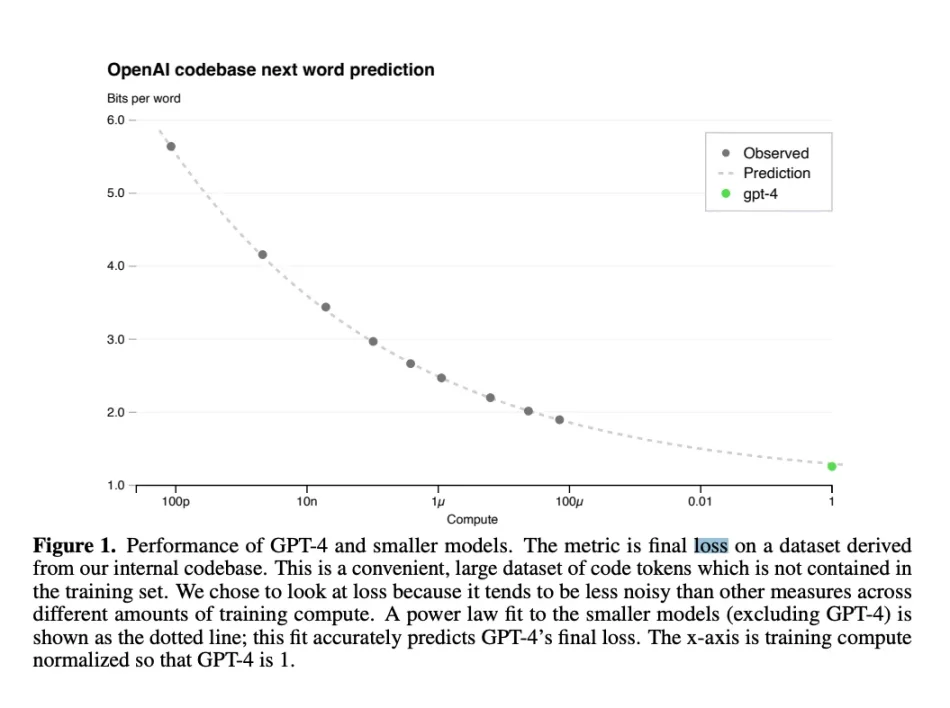
Regarding the loss function, here is the latest performance of sn 9 (relevant subnetwork) that I took from Discord yesterday, keep in mind that minimum loss does not necessarily mean average loss:
“If Bittensor itself doesn’t train the model, what else can it do?!”
In fact, the creation process of a large language model (LLM) is divided into three key stages, namely training, fine-tuning and contextual learning (adding a little reasoning).
Before we move on to some basic definitions, here’s a look at Sequoia Capital’s June 2023 article on LLMReport, their findings were: “Typically in addition to using the LLM API, 15% of companies built custom language models from scratch or based on open source libraries. Custom model training has increased significantly from just a few months ago. This requires you to Compute stacks, model hubs, hosting, training frameworks, experiment tracking, and more from beloved companies like Hugging Face, Replicate, Foundry, Tecton, Weights Biases, PyTorch, Scale, and more.”
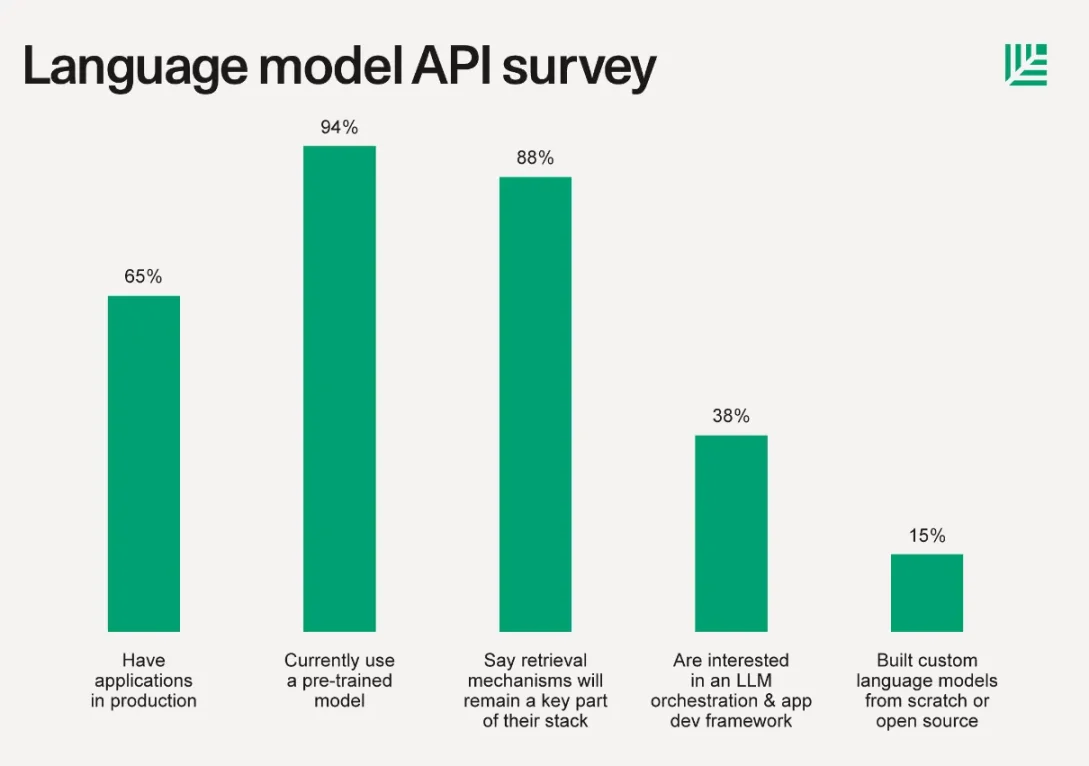
Building a model from scratch is a daunting task, and 85% of founders and teams surveyed were unwilling to undertake it. The workload of self-hosting, tracking results, creating or importing complex training scenarios and various other tasks is daunting when most startups and independent developers only want to leverage large language models in external applications or software-based services. too big. For 99% of the AI industry, creating something comparable to GPT-4 or Llama 2 is not feasible.
This is why platforms like Hugging Face are so popular because you can download already trained models from their website, a process that is very familiar and common to those in the AI industry.
Fine-tuning is more difficult, but suitable for those who want to provide large language model-based applications or services in a specific niche. This might be a legal services startup developing a chatbot with a model fine-tuned based on various lawyer-specific data and examples, or a biotech startup developing a model specifically based on possible biotech-related The information has been fine-tuned.

Whatever the purpose, fine-tuning is about further incorporating personality or expertise into your model, making it better suited and more accurate at performing tasks. While theres no denying its useful and more customizable, everyone agrees its difficult, even a16zthink:

Although Bittensor does not actually train the model, miners who submit their own models to the network claim to fine-tune the models in some form, although this information is not available to the public (or at least difficult to verify). The miner keeps its model structure and functionality secret to protect its competitive advantage, although some is accessible.
Let’s take a simple example: if you were participating in a competition with a $1 million prize, and everyone was competing to see who had the best-performing LLM, if all your competitors were using GPT-2, would you Reveal you are using GPT-4? Although the actual situation is more complicated than this example illustrates, it is not that different. Miners are rewarded based on their output accuracy, which gives them an advantage over miners who finetune less models or models with poorer average performance.
I mentioned contextual learning before, and this is probably the last piece of non-Bittensor information Ill cover, but contextual learning is a broadly defined process for guiding language models to achieve more desirable outputs. Inference is the process that a model continuously undergoes when evaluating inputs, and the results of its training may affect the accuracy of the output labels. While training is expensive, it only occurs when the model is ready to reach the training level specified by the team during model creation. Reasoning is always happening, and a variety of additional services are used to facilitate the reasoning process.
Bittensor status
With some background, Ill explore some details about Bittensor subnet performance, current functionality, and future plans. To be honest, it’s hard to find quality articles on this topic. Luckily, Bittensor community members sent me some messages, but even then, forming an opinion took a lot of work. I lurked in their Discord looking for answers, and in the process I realized Id been a member for about a month but hadnt viewed any of the channels (I never use Discord, more Telegram and Slack).
Anyway, I decided to take a look at what Bittensors initial vision was and heres what I found in a previous report:

Ill cover it in the next few paragraphs, but the composability theory doesnt hold up. There has been some research on this topic, the previous screenshot comes from defining Bittensor networks as sparse mixture models (this concept is a 2017 studypapersubmitted).
Bittensor has so many subnetworks that I felt the need to dedicate an entire section to them in this report. Believe it or not, although these are crucial to the usefulness of the web and underpin all technologies, Bittensor does not have a dedicated section on its website to describe these and how they work. I even asked on Twitter, but it seems that the secrets of subnets are only understood by those who hang out in Discord for hours and learn the operations of each subnet on their own. Despite the enormity of the task before me, I did some work.
Subnet 1 (often abbreviated as sn 1) is the largest subnet in the Bittensor network and is responsible for the text generation service. Among the top 10 validators of sn 1 (I use the same top 10 ranking for other subnets), there are about 4 million TAO staked, followed by sn 5 (responsible for image generation), which has about 3.85 million TAO Pledge. By the way, all this data is available atTaoStatsfound on .
The multimodal subnetwork (sn 4) has about 3.4 million TAOs, sn3 (data scraping) has about 3.4 million TAOs, and sn 2 (multimodal) has about 3.7 million TAOs. Another subnetwork that has grown rapidly recently is sn 11, which is responsible for text training and has a similar number of TAO pledges as sn 1.
Sn 1 is also the absolute leader in terms of miner and validator activity, with over 40/128 active validators and 991/1024 active miners. Sn 11 actually has the most miners of all subnets, with 2017/2048. The chart below depicts subnet registration costs over the past month and a half:
The current cost to register a subnet is 182.12 TAO, which is down significantly from the October peak of 7,800 TAO, although Im not entirely sure that number is accurate. Regardless, with over 22 registered subnetworks and Bittensors increasing attention, we will likely see more subnetworks registered in due course. Some of these subnetworks seem to be taking a while to gain traction.
As far as other subnetworks go, sn 9 is a cool subnetwork dedicated to training:

The following is the description of BittensorCrawl subnetinstruction of:

The subnetwork model is very unique and is an example of a common technique in machine learning research called mixture of experts (MoE), in which the model is divided into parts and provided with individual labels, rather than being assigned an entire task . This is interesting to me because Bittensor is not a unified model, but is actually a network of models that are queried in a semi-random manner. An example of this process is BitAPI, a product built on sn 1 that randomly samples the top 10 miners queried by inbound users. While there may be dozens or even hundreds of miners in any given subnetwork, the best-performing models receive greater rewards.
It is currently not feasible to combine or composite multiple models to add or stack functionality. This is not how large language models work. I tried to reason with community members, but I think its important to note that, as it stands, Bittensor is not an example of a unified collection of models, just a network of models with different capabilities.
Some have compared Bittensor to on-chain oracles with access to ML models. Bittensor separates the core logic of the blockchain from the verification of the sub-network, running the model off-chain to accommodate more data and higher computational costs, thereby achieving more powerful models. You may recall that the only process done on-chain is inference. See belowcontentLearn about Bittensor’s explanation:
I think a lot of people in the community are too focused on trying to convince everyone that Bittensor is going to change the world, when in fact they are just making progress in trying to change the way artificial intelligence and cryptocurrencies interact. It’s unlikely that they could transform the entire network of miners uploading models into an extremely smart supercomputer — that’s not how machine learning works. Even the best performing and most expensive models available are still years away from achieving the definition of artificial general intelligence (AGI).
As the machine learning community continues to iterate and new features are implemented, the definition of AGI often varies, but the basic idea is that AGI is able to reason, think, and learn exactly like a human. The core puzzle arises from the fact that scientists classify humans as beings with consciousness and free will, which is difficult to quantify in humans, let alone powerful neural network systems.
As it stands, subnetworks are a unique way of breaking down the various tasks associated with AI-based applications, and it is the responsibility of the community and teams to attract builders who want to take advantage of these core capabilities of the Bittensor Network.
It’s also worth adding here that Bittensor is very efficient in the field of machine learning outside of cryptocurrencies. Opentensor and Cerebras released the BTLM-3 b-8 k open source LLM as early as July this year. Since then, BTLM has been downloaded over 16,000 times on Hugging Face and has received very positive reviews.
Some say that due to BTLMs lightweight architecture, BTLM-3 b ranks high in the same category as Mistral-7 b and MPT-30 b, becoming the best model per VRAM. Below is a chart from the same tweet listing the models and their data accessibility classification, for which BTLM-3 b received a decent rating:
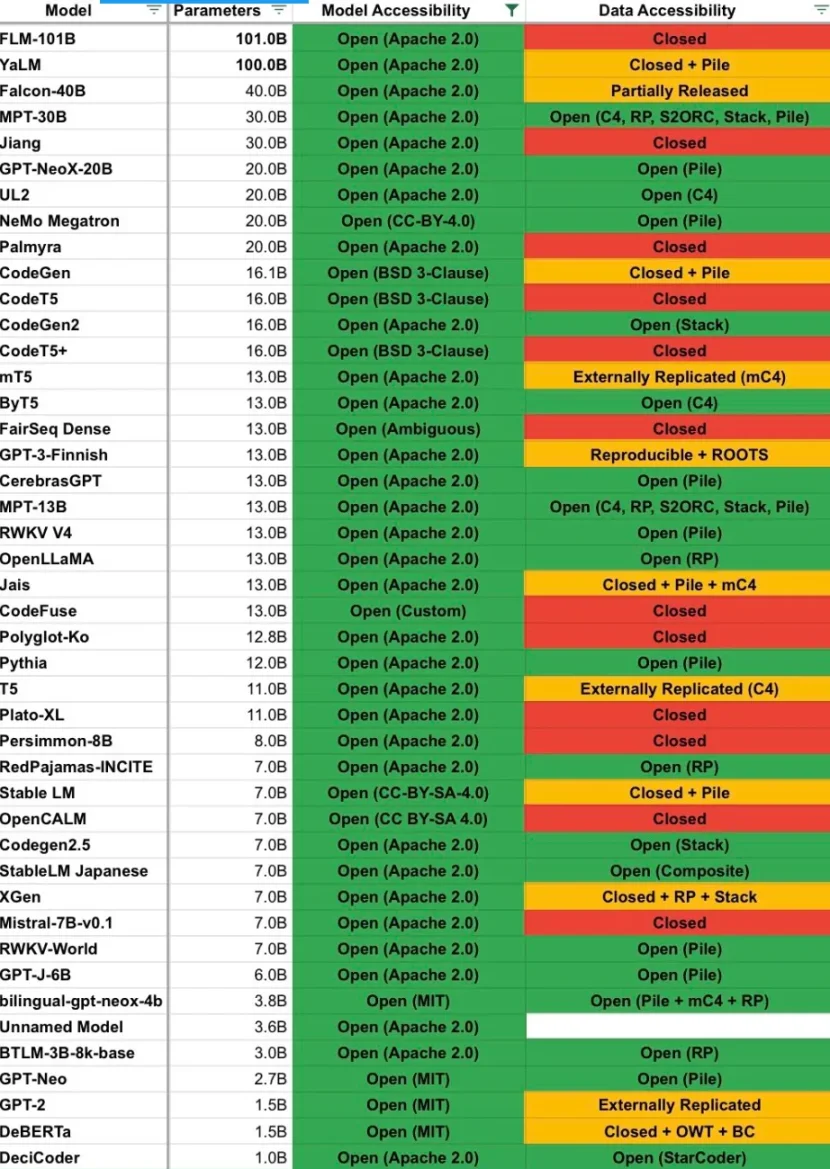
I said on Twitter that Bittensor doesnt do anything to accelerate AI research, so I think its only right that I admit my mistake here. Also, Ive heard that BTLM-3 b is used for verification in some cases since its cheap and runs fast on most hardware.
What is TAO used for?
Dont worry, I didnt forget the token.
Bittensor borrows a lot of inspiration from Bitcoin, but also draws from the OG textbook gameplay, and incorporates a very similar token economic structure, that is, a maximum of 21 million TAO and a halving mechanism every 10.5 million blocks. As of the time of writing this article, the number of TAOs in circulation is approximately 5.6 million, with a market value of nearly $800 million. The distribution of TAO is considered extremely fair, and this BittensorReportNoting that early backers did not receive any tokens, although it is difficult to verify the authenticity, we trust our sources.
TAO is both the reward token and the access token of the Bittensor network. TAO holders can stake, participate in governance or use their TAO to build applications on the Bittensor network. 1 TAO is minted every 12 seconds, and the newly minted tokens will be evenly distributed to miners and validators.
In my opinion, TAOs token economics easily envision a world where reducing release volume through halving results in increased competition among miners, naturally resulting in higher quality models and a better overall user experience. However, there is also a problem here, which is that smaller rewards will have the opposite effect and, instead of attracting strong competition, will lead to a stagnant number of deployed models or competing miners.
I could go on and on about TAO’s token utility, price outlook, and growth drivers, but the aforementioned report does a pretty good job on this. Most of Crypto Twitter has already established that there is a very solid narrative behind Bittensor and TAO, and nothing I can add at this point would further add to the icing on the cake. From an outside perspective, Id say these are pretty sound token economics and nothing out of the ordinary. I should mention though that buying TAO is currently very difficult as it is not yet listed on most exchanges. This situation may change in 1-2 months and I would be very surprised if Binance doesnt list TAO soon.
prospect
Im definitely a fan of Bittensor and hope they realize their bold mission. As the team at Bittensor ParadigmarticleAs stated in , Bitcoin and Ethereum are revolutionary because they democratize access to finance and make the idea of completely permissionless digital markets a reality. Bittensor is no exception and aims to democratize artificial intelligence models in vast intelligent networks. Despite my support, its clear that they are still far from what they want to achieve, which is true for most projects built with cryptocurrencies. This is a marathon, not a sprint.
If Bittensor wants to stay at the forefront, they need to continue to drive friendly competition and innovation among miners while expanding the possibilities of sparse hybrid model architectures, MoE ideas, and the concept of compounding intelligence in a decentralized manner. Doing all of this alone is difficult enough, adding encryption into the mix makes it even more challenging.
Bittensor still has a long road ahead. Although discussion around TAO has increased in recent weeks, I dont think most of the crypto community is fully aware of how Bittensor currently works. There are some obvious questions with no easy solutions, some of which are: a) whether high-quality large-scale inference is possible, b) the problem of engaging users and c) whether it makes sense to pursue the goal of composite large language models.
Believe it or not, supporting the decentralized currency narrative is actually quite a challenge, although rumors of ETFs are making it a little easier.
Building a decentralized network of intelligent models that iterate and learn from each other sounds too good to be true, and part of the reason is that it is. Within the current constraints of background windows and large language models, it is impossible for a model to improve itself over and over again until it reaches the point where with AGI, even the best models are still limited. Still, I think building Bittensor as a decentralized LLM hosting platform with novel economic incentives and built-in composability is more than just a positive, its actually one of the coolest experiments in crypto right now.
Integrating financial incentives into AI systems has its challenges, and Bittensor said that if miners or validators attempt to game the system in any form, they will adjust incentives on a case-by-case basis. Here’s an example from June this year, when token releases dropped by 90%:

This is completely to be expected in a blockchain system, so lets not pretend that Bitcoin or Ethereum will be 100% perfect throughout its life cycle.
Cryptocurrency adoption has historically been a difficult pill to swallow for outsiders, and artificial intelligence has been equally, if not more, controversial. Combining the two creates challenges for anyone to maintain user growth and activity, which will take some time. If Bittensor can ultimately achieve the goal of composite large language models, this could be a very significant thing.


