




TL;DR
第三次瀏覽器戰爭正在悄悄展開。回顧歷史,從90 年代的Netscape、微軟的IE,再到開源精神的Firefox 與Google 的Chrome,瀏覽器之爭一直是平台控制權與技術範式變化的集中體現。 Chrome 憑藉更新速度與生態連結奪得霸主地位,而Google 透過搜尋與瀏覽器的「雙寡頭」結構,形成了資訊入口的閉環。
但今天,這一格局正在動搖。大型語言模型(LLM)的崛起,使得越來越多用戶在搜尋結果頁「零點擊」完成任務,傳統的網頁點擊行為正在減少。同時,Apple 有意在Safari 中取代預設搜尋引擎的傳聞,進一步威脅Alphabet (Google 母公司) 的利潤根基,市場已開始顯露出對「搜尋正統」的不安。
瀏覽器本身也正面臨角色重塑。它不僅是展示網頁的工具,更是資料輸入、使用者行為、隱私身分等多種能力的集合容器。 AI Agent 雖強,但若要完成複雜的頁面互動、呼叫本機身分資料、控制網頁元素,仍需要藉助瀏覽器的信任邊界和功能沙盒。瀏覽器正在從人類介面,變成Agent 的系統呼叫平台。
在本文,我們探討了瀏覽器是否還有存在的必要,同時我們認為真正可能打破當前瀏覽器市場格局的,不是另一個“更好的 Chrome”,而是一種新的交互結構:不是資訊的展示,而是任務的調用。未來瀏覽器要為AI Agent 設計-不僅能讀,還能寫入和執行。像Browser Use 這樣的專案正嘗試將頁面結構語義化,把可視化介面變成LLM 可調用的結構化文本,實現頁面到指令的映射,極大降低交互成本。
市面上主流項目已開始試水:Perplexity 建立原生瀏覽器Comet,以AI 取代傳統搜尋結果;Brave 把隱私保護與本地推理結合,用LLM 增強搜尋與屏蔽功能;而Donut 等Crypto 原生項目,則瞄準AI 與鏈上資產交互的新入口。這些項目共同特徵是:試圖重構瀏覽器的輸入端,而非美化其輸出層。
對創業者而言,機會藏在輸入、結構與代理的三角關係中。瀏覽器作為未來Agent 調用世界的接口,意味著誰能提供可結構化、可調用、可信任的“能力塊”,誰就能成為新一代平台的組成部分。從SEO 到AEO(Agent Engine Optimization),從頁面流量到任務鏈調用,產品形態與設計思維都在重構。第三次的瀏覽器戰爭,發生在「輸入」而非「展示」;決定勝負的,不再是誰抓住用戶的眼球,而是誰贏得了Agent 的信任,獲得調用的入口。
瀏覽器發展簡史
在90 年代初,網路尚未成為日常生活的一部分時,Netscape Navigator 橫空出世,如同開啟新大陸的帆船,為數以百萬計的用戶打開了通往數位世界的大門。這款瀏覽器並非第一個,但卻是第一個真正意義上走向大眾、塑造網路體驗的產品。彼時,人們第一次能如此輕鬆地透過圖形介面瀏覽網頁,彷彿整個世界突然變得觸手可及。
然而,輝煌往往短暫。微軟很快就意識到瀏覽器的重要性,並決定將Internet Explorer 強行捆綁進Windows 作業系統,讓其成為預設瀏覽器。這項策略堪稱“平台殺手鐧”,直接瓦解了Netscape 的市場主導地位。許多使用者並非主動選擇IE,而是因為系統預設便接受了它。 IE 借助Windows 的分發能力,迅速成為產業霸主,Netscape 則陷入了衰敗的軌道。

Firefox Logo Evolution
在困境中,Netscape 的工程師選擇了一條激進而理想主義的道路——他們將瀏覽器原始碼公開,向開源社群發出召喚。這一決定,彷彿是一次技術界的“馬其頓式讓位”,預示著舊時代的終結與新力量的崛起。這段程式碼後來成為Mozilla 瀏覽器專案的基礎,最初命名為Phoenix(意為鳳凰涅槃),卻因商標問題幾經更名,最終定名為Firefox。
Firefox 並非簡單複製Netscape,它在使用者體驗、外掛程式生態、安全性等方面實現了多項突破。它的誕生標誌著開源精神的勝利,也為整個產業注入新的活力。有人形容Firefox 是Netscape 的“精神繼承者”,如同奧斯曼帝國繼承了拜占庭的餘暉。這一比喻雖誇張,卻頗具意味。
但在Firefox 正式發布前的幾年,微軟早已發布了六個版本的IE,憑藉時間優勢和系統捆綁策略,使Firefox 一開始便處於追趕地位,注定這場競賽並非起跑線平等的公平競爭。
同時,另一個早期玩家也在悄悄登場。 1994 年,Opera 瀏覽器問世,它來自挪威,起初只是一個實驗性專案。但從2003 年的7.0 版本起,它引入了自研的Presto 引擎,率先支援CSS、自適應佈局、語音控制以及Unicode 編碼等尖端技術。雖然用戶數量有限,但技術上始終走在行業前列,成為「極客的最愛」。
同年,蘋果推出了Safari 瀏覽器。這是一場別有意味的轉折。彼時,微軟曾向瀕臨破產的蘋果注資1.5 億美元,以維持競爭表象、避免反壟斷審查。雖然Safari 從誕生的預設搜尋引擎是Google,但這段與微軟的歷史糾葛象徵著網路巨頭之間複雜而微妙的關係:合作與競爭,總是如影隨形。
2007 年,IE 7 隨Windows Vista 推出,但市場回饋平平。反觀Firefox,憑藉更快的更新節奏、更友善的擴展機制以及對開發者的天然吸引力,市佔率穩步提升至約20% 。 IE 的統治逐漸鬆動,風向正在改變。
谷歌則是另一種打法。雖然從2001 年起就開始醞釀打造自家瀏覽器,但花了六年時間才說服CEO 艾瑞克‧施密特批准這個計畫。 Chrome 於2008 年問世,基於Chromium 開源專案與Safari 所使用的WebKit 引擎打造。它被戲稱為「臃腫」的瀏覽器,但憑藉谷歌對廣告投放與品牌塑造的深厚功力,迅速崛起。
Chrome 的關鍵武器並非功能,而是頻繁的版本更新節奏(每六週一次)與全平台統一體驗。 2011 年11 月,Chrome 首次超越Firefox,市佔率達到27% ;六個月後,又反超IE,完成了從挑戰者到主宰者的轉變。
同時,中國的行動互聯網也在形成自己的生態系統。阿里巴巴旗下的UC 瀏覽器在2010 年代初迅速躥紅,尤其是在印度、印尼、中國等新興市場,依靠輕量級設計、壓縮資料節省流量等特性,贏得了低端設備用戶的青睞。 2015 年,其全球行動瀏覽器市佔率突破17% ,在印度一度高達46% 。但這場勝利並不持久。隨著印度政府加強對中國應用的安全審查,UC 瀏覽器被迫退出關鍵市場,逐漸失去往日輝煌。
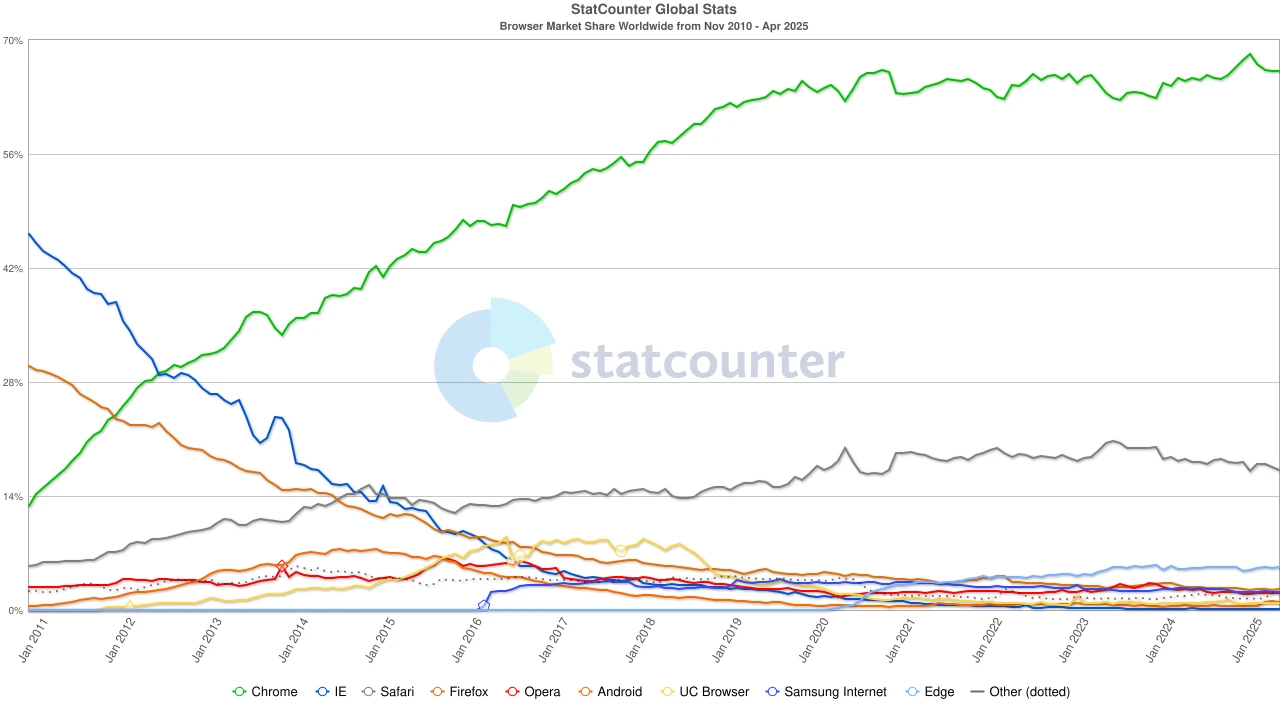
Browser market share, source: statcounter
進入2020 年代,Chrome 的主導地位已經確立,全球市佔率穩定在約65% 。值得注意的是,Google 搜尋引擎與Chrome 瀏覽器雖然同屬Alphabet,但從市場層面看卻是兩個獨立的霸權體系——前者控制了全球約九成的搜尋入口,後者則掌握了大多數用戶進入網路的「第一視窗」。
為了守住這雙重壟斷結構,Google不惜重金投入。 2022 年,Alphabet 向蘋果支付約200 億美元,只為讓Google 保持在Safari 中的預設搜尋地位。有分析指出,這筆支出相當於Google從Safari 流量中獲取搜尋廣告收入的36% 。換言之,Google正為護城河支付「保護費」。
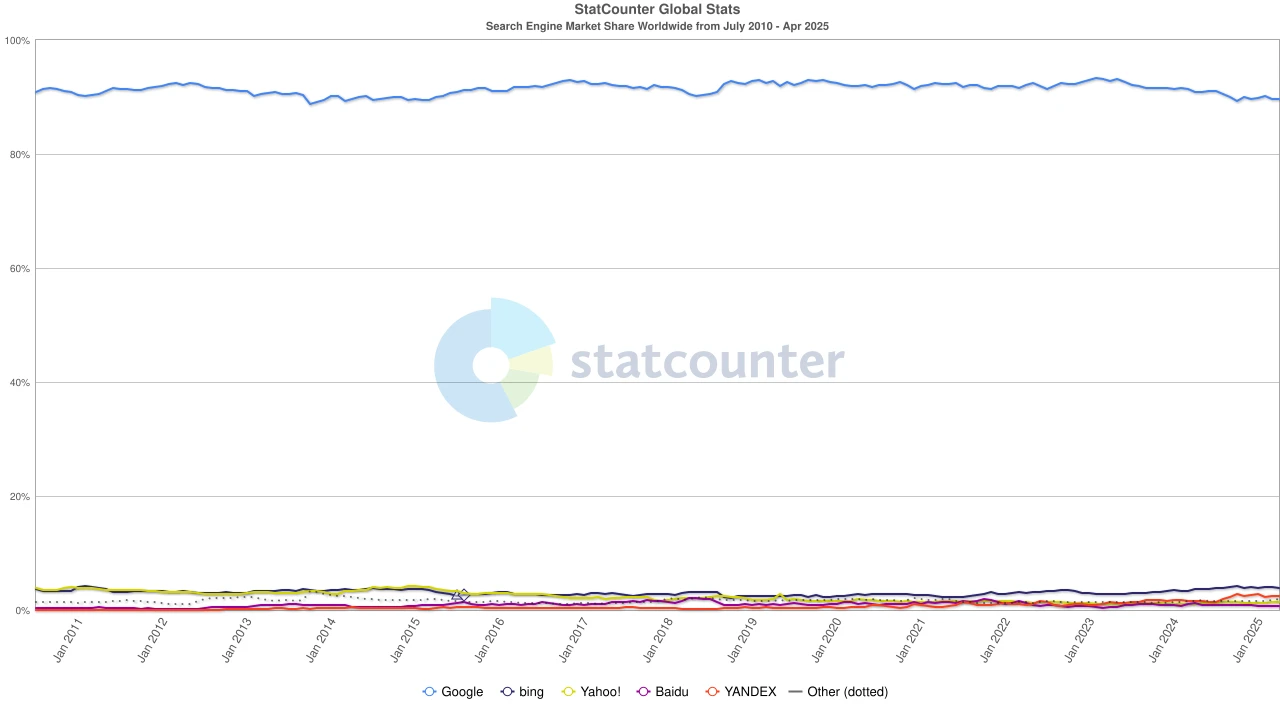
Search Engine market share, source: statcounter
但風向又一次變化。隨著大型語言模型(LLM)的崛起,傳統搜尋開始受到衝擊。 2024 年,Google 的搜尋市佔率自93% 跌至89% ,雖仍稱霸,但裂痕初現。更具顛覆性的,是關於蘋果或將推出自有AI 搜尋引擎的傳聞——若Safari 默認搜尋改投自家陣營,這不僅將改寫生態格局,更可能撼動Alphabet 的利潤支柱。市場反應迅速,Alphabet 股價從170 美元應聲下跌至140 美元,反映的不僅是投資人的恐慌,更是對搜尋時代未來走向的深度不安。
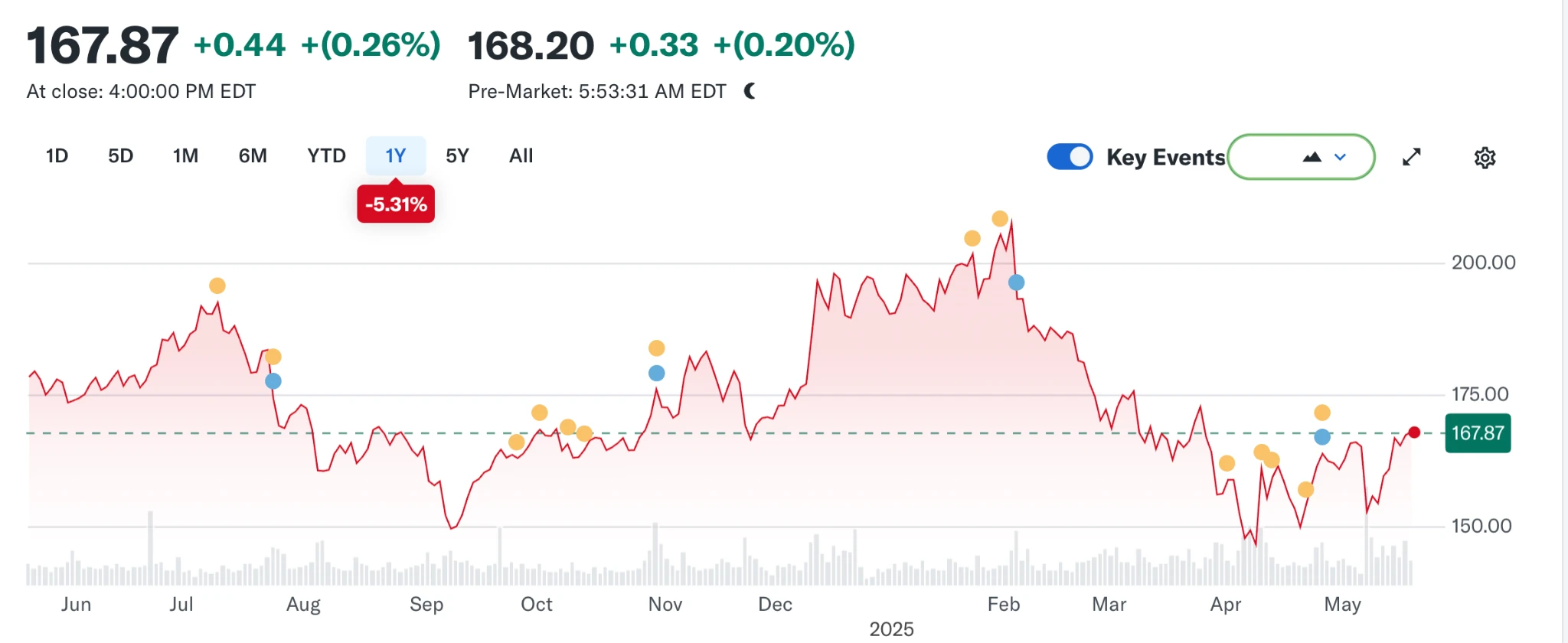
從Navigator 到Chrome,從開源理想到廣告商業化,從輕量瀏覽器到AI 搜尋助手,瀏覽器之爭始終是一場關於科技、平台、內容與控制權的戰爭。戰場不斷遷移,但本質從未改變:誰掌握入口,誰就定義未來。
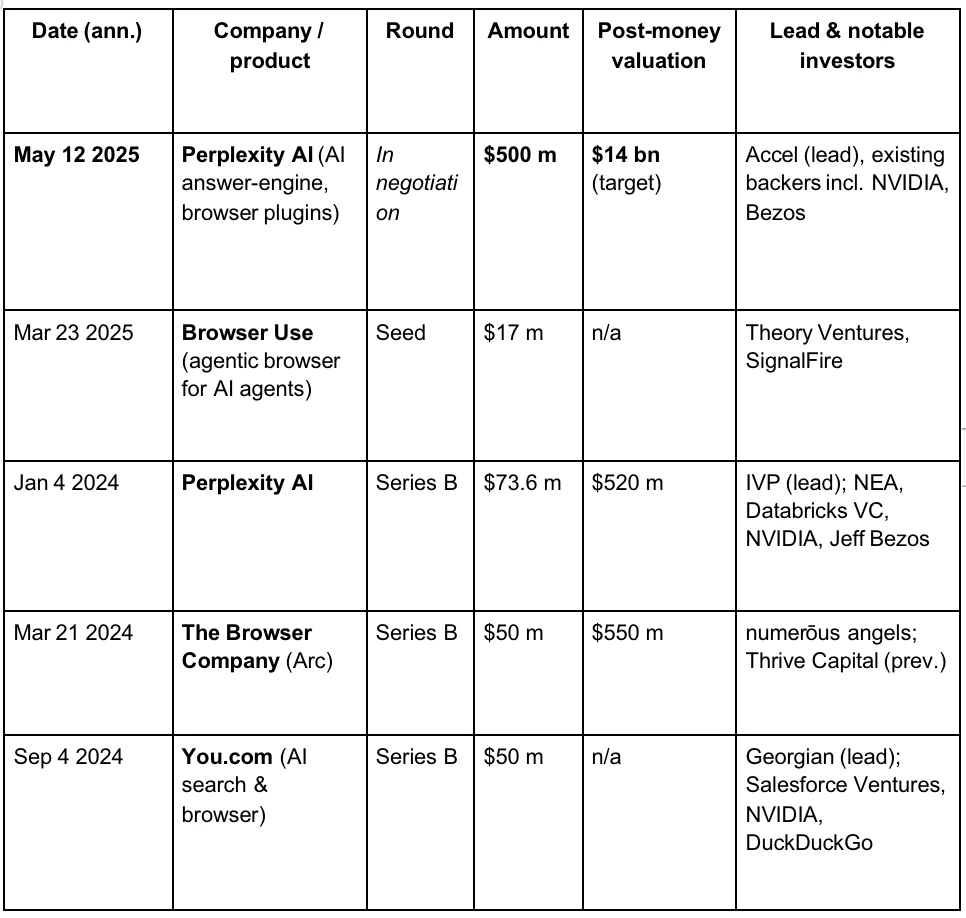
在VC 眼中,依托LLM 和AI 時代人們對搜尋引擎的新需求,第三次瀏覽器戰爭正在逐步展開。以下是部分知名AI 瀏覽器賽道的專案的融資情況。
現代瀏覽器的老舊架構
談到瀏覽器的架構,經典的傳統架構如下圖所示:
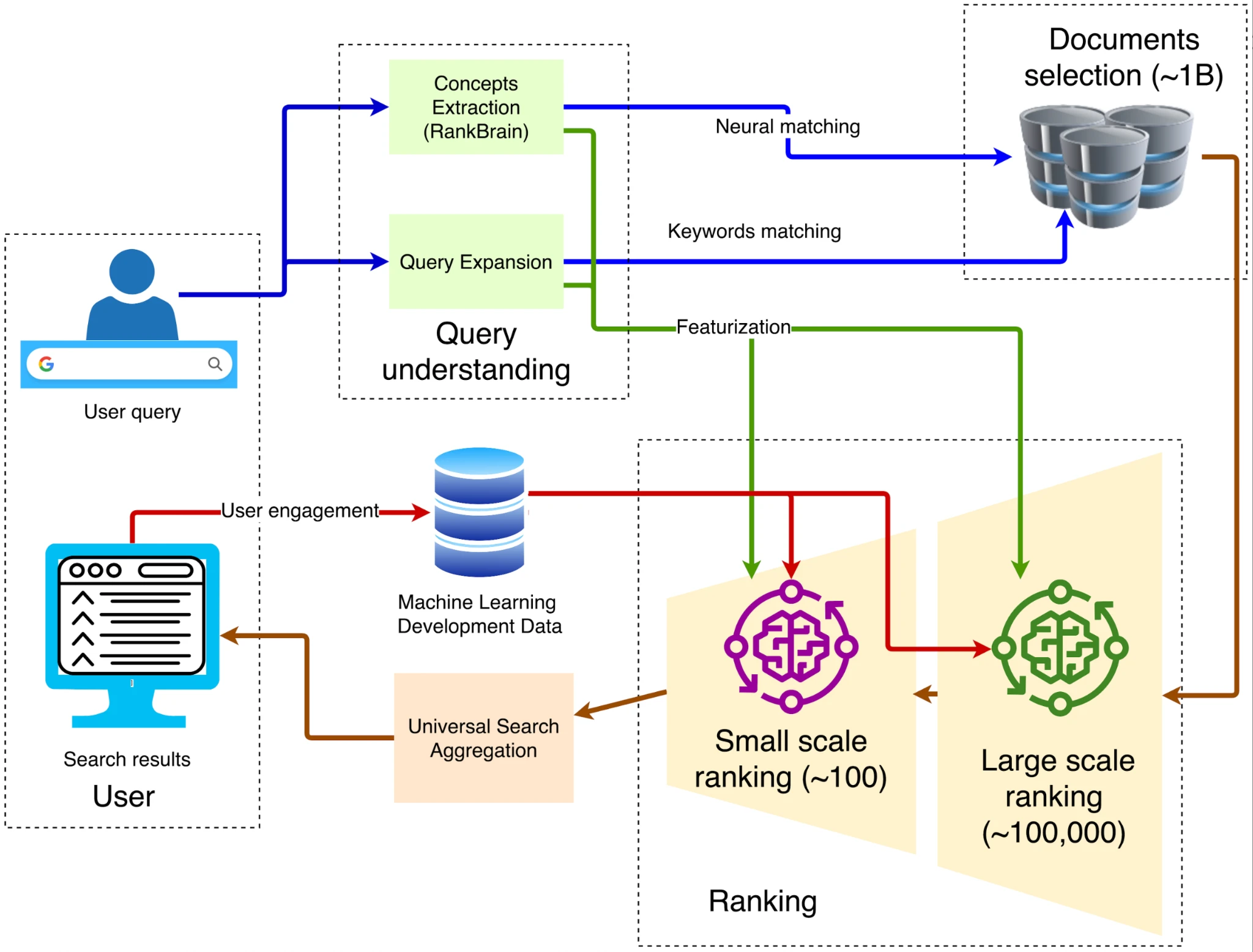
The overall architecture, source: Damien Benveniste
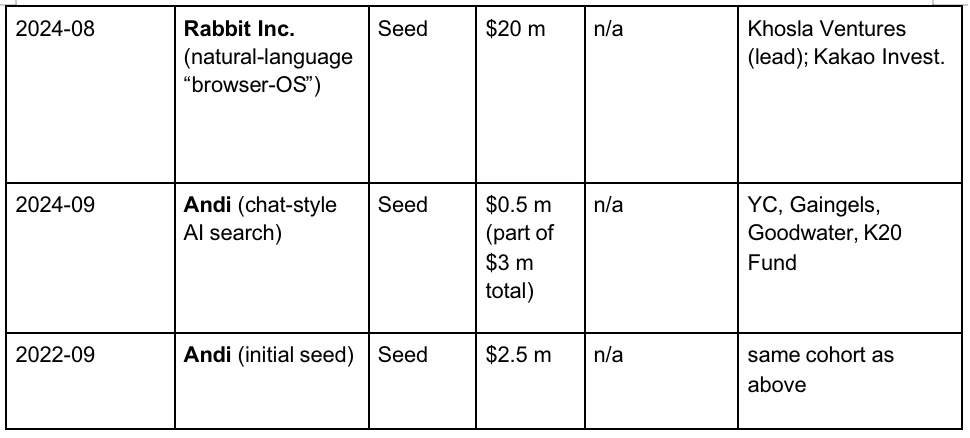
1. 客戶端- 前端入口
查詢經HTTPS 送達最近的Google Front End,完成TLS 解密、QoS 採樣和地理路由。若偵測到異常流量(DDoS、自動抓取)可在此層限流或挑戰。
2. 查詢理解
前端需要理解使用者鍵入的單字的含義,有三個步驟:神經拼字校正,將“recpie” 修正為“recipe”;同義詞擴展,將“how to fix bike”,拓展到“repair bicycle”。意圖解析,判定查詢是資訊、導航或交易意圖,並分配Vertical 請求。
3. 候選召回
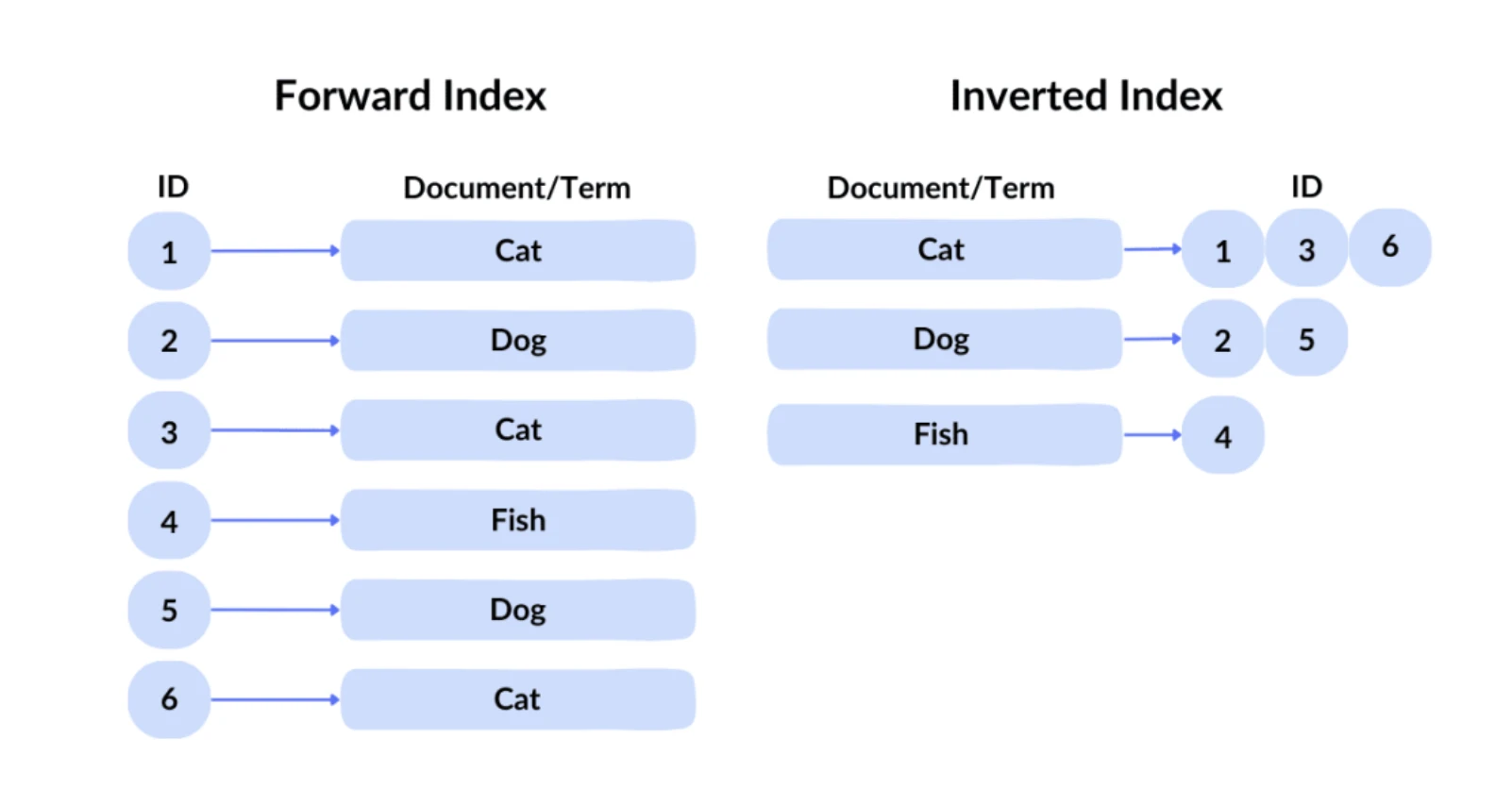
Inverted Index, source:spot intelligence
Google 所使用的查詢技術稱為:倒排索引。在正序索引中,我們都是給定一個ID 就可以索引到檔案。但是使用者不可能知道想要的內容在上千億個檔案中的編號,因此其採用了非常傳統的倒排索引,透過內容來查詢到哪些檔案有對應的關鍵字。接下來,Google 採用向量索引用於處理語意搜索,即查找與查詢意義相似的內容。它將文字、圖像等內容轉換為高維向量(embedding),並根據這些向量之間的相似性進行搜尋。例如,即使用戶搜尋“如何製作披薩麵團”,搜尋引擎也能返回與“披薩麵團製作指南”相關的結果,因為它們在語義上相似。經歷了倒排索引和向量索引,大約十萬量級的網頁會被初步篩選出來。
4. 多級排序
系統通常透過B M2 5、TF-IDF、頁面品質分等數千維輕特徵,將十萬級規模的候選頁面篩選至約1000 篇,構成初步候選集。這類系統統稱為推薦引擎。其依賴多種實體產生的海量特徵,包括使用者行為、頁面屬性、查詢意圖與上下文訊號。例如,Google 會綜合用戶歷史、其他用戶的行為反饋、頁面語義、查詢含義等信息,同時還考慮上下文要素,如時間(一天中時段、一周中的具體日子)與實時新聞等外部事件。
5. 深度學習進行主排序
在初步檢索階段,Google 使用RankBrain 和Neural Matching 等技術來理解查詢的語義,並從海量文件中篩選出初步相關的結果。 RankBrain 是Google 於2015 年引入的機器學習系統,旨在更好地理解使用者查詢的含義,尤其是首次出現的查詢。它透過將查詢和文件轉換為向量表示,計算它們之間的相似性,從而找到最相關的結果。例如,對於查詢“如何製作披薩麵團”,即使文件中沒有完全匹配的關鍵字,RankBrain 也能識別出與“披薩基礎”或“麵團製作”相關的內容。
Neural Matching 是Google 於2018 年推出的另一項技術,旨在更深入地理解查詢和文件之間的語義關係。它使用神經網路模型來捕捉詞語之間的模糊關係,幫助Google 更好地匹配查詢和網頁內容。例如,對於查詢“為什麼我的筆記型電腦風扇聲音很大”,Neural Matching 能夠理解用戶可能在尋找有關過熱、灰塵積聚或高CPU 使用率的故障排除信息,即使這些詞語沒有直接出現在查詢中。
6. 深度重排:BERT 模型的應用
在初步篩選出相關文件後,Google 使用BERT(Bidirectional Encoder Representations from Transformers)模型對這些文件進行更精細的排序,以確保最相關的結果排在前面。 BERT 是一種基於Transformer 的預訓練語言模型,能夠理解詞語在句子中的上下文關係。在搜尋中,BERT 被用來重新排序初步檢索到的文件。它透過對查詢和文件進行聯合編碼,計算它們之間的相關性得分,從而對文件進行重新排序。例如,對於查詢“停車在沒有路緣的坡道上”,BERT 能夠理解“沒有路緣”的含義,並返回建議駕駛員將車輪朝向路邊的頁面,而不是誤解為有路緣的情況。而對於SEO 工程師來說,就是需要精確的學習Google 排序和機器學習的推薦演算法,來針對性的優化網頁內容重而獲得更高的排名展示。
以上就是典型的Google 搜尋引擎的工作流程。但是在當前的AI 和大數據爆發的時代,用戶對瀏覽器的互動產生了新的需求。
為什麼AI 會重塑瀏覽器
首先我們要先明確,為什麼瀏覽器這形態仍然會存在?是否存在一種第三形態,除了人工智慧代理和瀏覽器之外的選擇?
我們認為,存在即無法取代。為什麼人工智慧能夠使用瀏覽器,卻無法完全取代瀏覽器?因為瀏覽器是通用平台,不只是讀取資料的入口,更是輸入資料的通用入口。這個世界不可能只有資訊輸入,還必須產生數據並與網站進行交互,所以整合個人化用戶資訊的瀏覽器仍將廣泛存在。
我們抓住這個點:瀏覽器作為通用入口,不僅用於讀取數據,用戶往往還需要與數據互動。瀏覽器本身是儲存使用者指紋的絕佳場所。更複雜的使用者行為和自動化行為,必須以瀏覽器為載體。瀏覽器可以儲存使用者的所有行為指紋、通行證等隱私訊息,在自動化過程中實現無需信任的呼叫。而與數據互動的動作,可以演變為:
使用者→ 呼叫AI Agent → 瀏覽器。
也就是說,唯一可能被取代的部分,就是符合世界演變趨勢的方向——更聰明、更個人化、更自動化。誠然,這部分可以交給AI Agent 來處理,但AI Agent 本身絕非適合承載用戶個人化內容的場所,因為其在資料安全與便利性方面面臨多重挑戰。具體而言:
瀏覽器是個人化內容的儲存場所:
1. 多數大型模型託管在雲端,會話情境依賴伺服器保存,難以直接呼叫本機密碼、錢包、Cookie 等敏感資料。
2. 將全部瀏覽和支付資料送到第三方模型,需重新獲得使用者授權;歐盟《DMA》與美國州級隱私法均要求資料最小化出境。
3. 自動填寫雙重驗證驗證碼、呼叫相機或利用GPU 進行WebGPU 推理,都必須在瀏覽器沙盒內完成。
4. 資料上下文高度依賴瀏覽器,包括標籤頁、Cookie、IndexedDB、Service Worker Cache、Passkey 憑證以及擴充數據,都沉澱在瀏覽器中。
互動形式的深刻變革
回到剛開始的話題,我們使用瀏覽器的行為大致可以分為三種形式:讀取資料、輸入資料、互動資料。人工智慧大模型(LLM)已經深刻改變了我們讀取資料的效率和方式,過去用戶基於關鍵字搜尋網頁的行為顯得非常老舊且低效。
針對使用者搜尋行為的演變-是取得總結答案,還是點擊網頁,已經有不少研究進行分析。
在使用者的行為模式方面, 2024 年的研究顯示,在美國每1, 000 次Google 查詢中,只有374 次最終點擊開放網頁。換言之,近63% 屬於「零點擊」行為。使用者習慣直接從搜尋結果頁面取得天氣、匯率、知識卡等資訊。
在使用者的心理方面,一項2023 年的調查指出, 44% 受訪者認為常規自然結果比精選摘要(featured snippet)更值得信賴。學術研究也發現,在有爭議或無統一真相的議題中,使用者更偏好包含多來源連結的結果頁。
也就是說,確實有一部分使用者對AI 摘要的信賴度不高,但也有相當比例的使用者行為已經轉向「零點擊」。所以,AI 瀏覽器仍然需要探索一個恰當的互動形態-特別是在資料讀取這一部分,因為目前大模型的「幻覺問題」(hallucination)仍未根除,許多使用者仍難以完全信任自動產生的內容摘要。在這方面,如果將大模型嵌入瀏覽器,實際上不需要對瀏覽器進行顛覆性變革,只需逐步解決模型的準確性與可控性,這項改進也正在持續推進中。
而真正可能觸發瀏覽器大規模變革的,才是資料互動這一層。過去人們透過輸入關鍵字完成互動——這是瀏覽器能理解的極限。而現在,使用者越來越傾向於使用一整段自然語言來描述複雜任務,例如:
● “尋找紐約到洛杉磯某個時段的直升機機票”
● “尋找紐約飛上海然後到洛杉磯的機票”
這些行為,即使對人類來說也需要耗費大量時間去造訪多個網站、收集與比較資料。但這些Agentic Tasks(代理任務)正逐步被AI Agent 接手。
這也符合歷史演進的方向:自動化與智慧化。人們渴望解放雙手,AI Agent 必將深度嵌入瀏覽器中。未來的瀏覽器必須為全自動化而設計,尤其要考慮:
● 如何兼顧人類閱讀經驗與AI Agent 可解析性,
● 如何在同一個頁面上,既服務於用戶,也服務於代理模型。
只有滿足這兩者的設計,瀏覽器才能真正成為AI Agent 執行任務的穩定載體。
接下來,我們將聚焦在五個備受關注的項目,包括Browser Use、Arc(The Browser Company)、Perplexity、Brave 以及Donut。這些項目分別代表了AI 瀏覽器的未來演進方向,及其在Web3 和Crypto 場景中的原生結合潛力。
Browser Use
這正是Perplexity 和Browser Use 獲得巨額融資背後的核心邏輯。尤其是Browser Use,是2025 年上半年湧現的第二個最具確定性與成長潛力的創新機會。

Browser Use, source: Browser Use
Browser 是建構了一個真正意義上的語意層,其核心在於為下一代瀏覽器建立了語意辨識架構。
Browser Use 將傳統「DOM=給人看的節點樹」重新解碼成「語意DOM=給LLM 看的指令樹」,讓代理無需「看片點座標」就能精準點擊、填寫與上傳;這條路線以「結構化文字→ 函數呼叫」取代視覺OCR 或座標更快、更虛擬省TechCrunch 稱之為“讓AI 真正讀懂網頁的膠水層”,而3 月完成的1700 萬美元種子輪正是押注這一底層革新。
HTML 渲染後形成標準DOM 樹;瀏覽器再衍生一棵accessibility tree,為螢幕閱讀器提供更豐富的「角色」與「狀態」標籤。
1. 把每個可交互元素(<button>,<input> 等)抽象化成JSON 片段,附帶角色、可見性、座標、可執行動作等元資料;
2. 將整棵頁面轉譯成扁平化「語意節點清單」,供LLM 在系統提示裡一次讀取;
3. 接收LLM 輸出的高層指令(如click(node_id=btn-Checkout)),回放到真瀏覽器。官方部落格把這個過程稱作“把網站介面變成LLM 可解析的structured text”
同時,一旦這套標準被引入 W 3 C,那麼可以很大程度上解決瀏覽器輸入的問題。我們以 The Browser Company 的公開信和案例,來進一步闡述為什麼 The Browser Company 的想法是錯的。
Arc
The Browser Company (Arc 母公司) 在公開信中表示,ARC 瀏覽器將進入常規維護階段,團隊將重心會放在完全以AI 為導向的瀏覽器DIA。信中也坦言,目前尚未確定DIA 的具體實現路徑。同時,團隊在信中提出了若干對未來瀏覽器市場的預測。基於這些預測,我們進一步認為,若要真正顛覆現有瀏覽器格局,關鍵在於對互動側的輸出做出改變。
以下是我們截取的三個來自ARC 團隊對未來瀏覽器市場的預測。
Webpages wont be the primary interface anymore. Traditional browsers were built to load webpages. But increasingly, webpages — apps, articles, and files — will become tool calls with AI chat interfaces. In man interface faces interface face interface interface interface faces interfaces 303 月 chat interface man interfaceers 3y face interfaces, 3face interfaceerss 38l 3faces 3303033:73s 3faces faces外:Phat ekcl man一邊search, read, generate, respond. They interact with APIs, LLMs, databases. And people are spending hours a day in them. If youre skeptical, call a cousin in high school or college — natural land interface interface interfacestract rmuralstract adfaceurals , n; paradigms, are here to stay.
But the Web isnt going anywhere — at least not anytime soon. Figma and The New York Times arent becoming less important. Your boss isnt ditching your teams SaaS tools., opposite. Weite the opposite. llals SaaS tools., opposite. articles from our favorite publishers. Said。 chat interface — itll be both. Like peanut butter and jelly. Just as the iPhone combined old categories into something radically new, so too will AI browsers. Even if its not ours that wins.
New interfaces start from familiar ones. In this new world, two opposing forces are simultaneously true. How we all use computers is changing much faster (due to AI) than most people acknowledge. Yet farweal time, far thefar yes, far thefar yek s thefar sh leh. than AI insiders give credit for. Cursor proved this thesis in the coding space: the breakthrough AI app of the past year was an (old) IDE — designed to be AI-native. OpenAI confirmed this theory when the bought Windsurf believe AI browsers are next.
首先,其認為Webpages 不再成為主要的互動介面。不可否認,這是一個具有挑戰性的判斷,也正是我們對其創辦人反思結果保留態度的關鍵。在我們看來,該觀點顯著低估了瀏覽器的作用,也正是其在探索AI 瀏覽器路徑時忽略的關鍵問題。
大模型在意圖捕捉方面表現優異,例如理解「幫我訂機票」這樣的指令。然而,在資訊密度承載能力上,它們仍顯不足。當使用者需要一個如儀錶板、彭博終端風格的記事本,或類似Figma 的可視化畫布時,沒有什麼能比像素級精度排列的專用網頁更具優勢。每款產品都量身訂製的人體工學設計——圖表、拖放功能、熱鍵——並非裝飾性的浮渣,而是壓縮認知的可供性。這些能力是簡單對話式互動無法承載的。以Gate.com 為例,若使用者希望進行投資操作,僅依賴AI 對話遠遠不夠,因為使用者對資訊輸入、精確度與結構化呈現有著高度依賴。
RC 團隊在其路徑設想中存在一個本質偏差,即未能清晰地區分「交互」由輸入與輸出兩個維度構成。在輸入側,其觀點在某些場景下具有一定合理性,AI 的確可以提升指令式互動的效率;但在輸出側,此判斷明顯失衡,忽略了瀏覽器在資訊呈現與個人化體驗中的核心作用。例如,Reddit 擁有其獨特的佈局方式與資訊架構,而AAVE 則有著完全不同的介面與結構。瀏覽器作為一個既容納高度私密性數據,又能通用渲染多樣化產品介面的平台,瀏覽器在輸入層的替代性本就有限,而在輸出側,其複雜性與不可標準化特性更使其難以被顛覆。相較之下,目前市面上的AI 瀏覽器更集中在「輸出總結」層面:摘要網頁、提煉資訊、產生結論,尚不足以構成對Google 等主流瀏覽器或搜尋體系的根本性挑戰,分瓜的也只是搜尋總結的市場份額。
因此,真正能夠撼動市場份額高達66% 的Chrome 的,注定不會是「下一個Chrome」。要實現這一顛覆,必須對瀏覽器的渲染模式進行根本性重塑,使其能夠適配智慧時代AI Agent 主導下的互動需求,尤其是在輸入側的架構設計上。正因如此,我們更認可Browser Use 所採取的技術路徑──其關注點在於瀏覽器底層機制的結構性變革。任何系統一旦實現“原子化”或“模組化”,其由此衍生出的可編程性與組合性將帶來極具破壞力的顛覆潛力,而這正是Browser Use 目前所推進的方向。
總結而言,AI Agent 的運作仍高度依賴瀏覽器的存在。瀏覽器不僅是複雜個人化資料的主要儲存場所,也是多樣化應用的通用渲染介面,因此將在未來繼續作為核心互動入口。隨著AI Agent 深度嵌入瀏覽器以完成固定任務,其將透過呼叫使用者資料與特定應用程式進行交互,即主要作用於輸入側。為此,瀏覽器的現有渲染模式需進行創新,以實現對AI Agent 的最大程度相容與適配,從而更有效地捕捉應用。
Perplexity
Perplexity 是以其推薦系統而聞名的AI 搜尋引擎,最新估值高達 140 億美元,較2024 年6 月的30 億美元成長近5 倍。月均處理搜尋查詢量超過4 億次, 2024 年9 月處理了約2.5 億次查詢,用戶查詢量年增8 倍,每月活躍用戶超過3,000 萬。
其主要的特點是能夠即時的總結頁面,在獲取即時資訊方面佔據優勢。今年初,其開始建立自己的原生瀏覽器Comet。 Perplexity 把即將發布的Comet 描述成一個不僅「顯示」網頁、更能「思考」網頁的瀏覽器。官方稱它將在瀏覽器內部深度嵌入Perplexity 的答案引擎,這是賈伯斯式的「整機」思路:將AI 任務深埋到瀏覽器底層,而非做側邊欄插件。用帶有引用的簡潔答案取代傳統的“十條藍色鏈接”,直接與Chrome 競爭。

Google I/O 2025
但其仍需解決兩個核心問題:高搜尋成本以及來自邊際用戶的低利潤率。儘管Perplexity 在AI 搜尋領域已處於領先位置,但Google 在2025 年I/O 大會上同樣宣布對其核心產品進行大規模智慧化重塑。針對瀏覽器的重塑,Google 推出了一個新的瀏覽器標籤頁體驗,名為AI Model,整合了Overview、Deep Research 以及未來的Agentic 功能,整體專案被稱為「Project Mariner」。
Google 正在積極的進行AI 重塑,因此僅憑表層的功能模仿,例如Overview、DeepResearch 或 Agentics,難以真正對其構成威脅。真正有可能在混沌中建立新秩序的,將是從底層重構瀏覽器架構、將大語言模型(LLM)深度嵌入瀏覽器內核,在交互方式上實現根本性的變革。
Brave
Brave 是Crypto 產業裡面最早期也是最成功的瀏覽器,其基於Chromium 架構,因此能夠與 Google Store 上的插件相容。其依靠隱私和瀏覽來賺取Tokens 這一模式來吸引用戶。 Brave 的發展路徑在某種程度上展現了其成長潛力。但從產品角度來看,隱私固然重要,但其需求仍主要集中在特定使用者群體,對大眾而言隱私意識尚未成為主流決策因素。因此,試圖依靠該特性顛覆現有巨頭的可能性較低。
截至目前,Brave 的月活躍用戶已達8, 270 萬,每日活躍用戶為3, 560 萬,市佔率約1% – 1.5% 。用戶規模呈持續成長態勢:從2019 年7 月的600 萬,成長至2021 年1 月的2, 500 萬, 2023 年1 月達5, 700 萬,至2025 年2 月突破8, 200 萬,年均複合成長率仍維持在兩位數水準。其月均搜尋查詢量約為13.4 億次,約為Google 的0.3% 。
以下是 Brave 的迭代路線圖。
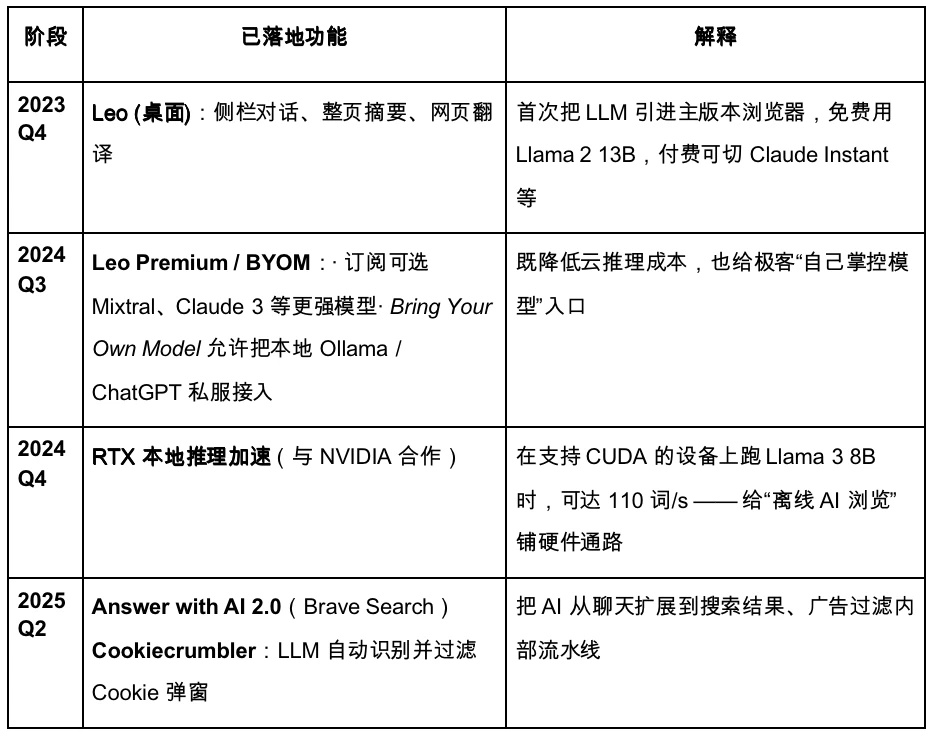
Brave 正計劃升級為隱私優先的AI 瀏覽器。然而,受限於其獲取用戶數據較少,導致大模型的可客製化程度較低,反而不利於實現快速且精準的產品迭代。在即將到來的Agentic Browser 時代,Brave 或將在特定注重隱私的用戶群中保有穩定份額,但難以成為主要玩家。其AI 助理Leo 更類似於外掛插件,僅在現有產品基礎上進行功能性增強,具備一定的內容總結能力,但尚無全面轉向AI Agent 的明確戰略,交互層面的革新仍顯不足。
Donut
近期,Crypto 產業在Agentic Browser 領域也有所進展。新創計畫Donut 在Pre-seed 輪獲得了700 萬美元融資,由紅杉中國(Hongshan)、HackVC 與Bitkraft Ventures 共同領投。目前專案仍處於早期構想階段,願景在於實現「探索—決策—加密原生執行」(Discovery, Decision-making, and Crypto-native Execution)的一體化能力。
這一方向的核心在於結合加密原生的自動化執行路徑。正如a16z 所預言,未來Agent 有望取代搜尋引擎成為主要流量入口,創業者將不再圍繞Google 排序演算法展開競爭,而是爭奪由Agent 執行所帶來的存取和轉換流量。業界已將這一趨勢稱為「AEO」(Answer / Agent Engine Optimization),或更進一步的「ATF」(Agentic Task Fulfilment),即不再優化搜尋排名,而是直接服務於能夠替用戶完成下單、訂票、寫信等任務的智慧模型。
給創業者
首先,必須承認:Browser 本身依舊是網路世界最大的未被重構的「總入口」。全球桌面用戶約21 億、行動裝置超43 億,它是資料輸入、互動行為、個人化指紋儲存的共同載體。這個形態之所以存續,不是因為慣性,而是因為瀏覽器天然具備雙向屬性:既是數據“讀取入口”,也是行為“寫入出口”。
因此,對於創業者而言,真正具備顛覆潛力的並非「頁面輸出」層面的最佳化。即便能在新分頁中實現類似Google 的AI 概覽功能,本質上仍屬於瀏覽器插件層的迭代,尚未構成範式的根本性變革。真正的突破口在於「輸入側」——即如何使AI Agent 主動調用創業者的產品,以完成具體任務。這將成為未來產品能否嵌入Agent 生態、獲得流量與價值分配的關鍵。
搜尋時代拼「點選」;代理時代拼「呼叫」。
如果你是創業者,不妨把你的產品重新想像成一顆API 元件——讓智能體不僅能「讀懂」它,更能「呼叫」它。這就要求你在產品設計一開始就考慮三個維度:
一、介面結構標準化:你的產品是「可調用」的麼?
產品是否具備被智慧體調用的能力,取決於其資訊結構能否標準化並抽象化為明確的schema。例如,使用者註冊、下單按鈕、評論提交等關鍵操作,是否可透過語義化的DOM 結構或JSON 映射進行描述?系統是否提供狀態機,讓Agent 能穩定復現使用者行為流程?使用者在頁面上的互動是否支援腳本化還原?是否具備穩定存取的WebHook 或API Endpoint?
這正是Browser Use 融資成功的本質原因——它將瀏覽器從平鋪渲染的HTML 轉變為一棵可被LLM 呼叫的語意樹。對於創業者而言,在網頁產品中引入類似的設計理念,即是在為AI Agent 時代進行結構化適配。
二、身分與通行:你能幫Agent「越過信任障壁」嗎?
AI 代理要完成交易、調用支付或資產,需要某種可信中間層——你能成為它嗎?瀏覽器天然可以讀取本機儲存、呼叫錢包、識別驗證碼、存取雙因子驗證,這正是它比雲端大模型更適合做執行的原因。在Web3 場景中尤其如此:呼叫鏈上資產的介面標準並不統一,Agent 若無“身分”或“簽章能力”,將寸步難行。
所以,對Crypto 創業家而言,這裡有一個極具想像的空白區:「區塊鏈世界的MCP(Multi Capability Platform)」。這既可以是一個通用指令層(讓Agent 呼叫Dapp),也可以是標準化的合約介面集,甚至是某種運行在本地的輕量錢包+身分中台。
三、流量機制的再理解:未來不是SEO,是AEO / ATF
過去你要爭取Google 的演算法青睞;現在你要被AI Agent 嵌入進任務鏈裡。這意味著產品要有清晰任務顆粒度:不是一個“頁面”,而是一串“可調用能力單元”;意味著你要開始做Agent 優化(AEO)或任務調度適配(ATF):例如註冊流程是否可簡化為結構化步驟、定價是否可通過接口拉取、庫存是否實時可查;
你甚至要開始適配不同LLM 框架下的呼叫語法——OpenAI 和Claude 對函式呼叫、tool usage 的偏好並不一致。 Chrome 是通往舊世界的終端,而不是通往新世界的入口。真正有未來的創業項目,不是再造一個瀏覽器,而是讓現有瀏覽器為Agent 服務,為新一代的「指令流」建立橋樑。
你要建構的,是Agent 呼叫你的世界的「介面語法」;
你要爭取的,是成為智能體信任鏈中的一環;
你要搭建的,是下一個搜尋模式裡的「API 城堡」。
如果說Web2 是靠UI 抓住使用者的注意力,那Web3 + AI Agent 時代,就是靠呼叫鏈抓住Agent 的執行意圖。
免責聲明:
本內容不構成任何要約、招攬、或建議。您在做出任何投資決定之前應始終尋求獨立的專業建議。請注意, Gate及/或Gate Ventures 可能會限製或禁止來自受限地區的所有或部分服務。請閱讀其適用的用戶協議以了解更多資訊。
關於Gate Ventures
Gate Ventures 是Gate 旗下的創投部門,專注於對去中心化基礎設施、生態系統和應用程式的投資,這些技術將在Web 3.0 時代重塑世界。 Gate Ventures 與全球產業領袖合作,賦予那些擁有創新思維和能力的團隊和新創公司,重新定義社會和金融的互動模式。
官網:https://ventures.gate.io/
Twitter:https://x.com/gate_ventures
Medium:https://medium.com/gate_ventures





