
Giải thích về Bittensor: Tăng 400% trong tháng 1, chú ngựa ô trên đường đua AI+Crypto
Tác giả gốc: Người biết
Tổng hợp gốc: Luffy, Tin tức tầm nhìn xa
Tin tức liên quan:

Bạn bè, lâu rồi không gặp. Tôi hy vọng tất cả các bạn đều thích thú với một số hành động giá tích cực gần đây trong không gian tiền điện tử. Để nhận được phần thưởng xứng đáng, tôi quyết định viết báo cáo chính thức về dự án mã hóa trí tuệ nhân tạo Bittensor. Tôi không phải là chuyên gia về tiền điện tử nên bạn có thể cho rằng tôi không rành lắm về trí tuệ nhân tạo. Tuy nhiên, trên thực tế, tôi dành nhiều thời gian rảnh rỗi để nghiên cứu AI bên ngoài tiền điện tử và đã làm quen với các cập nhật, tiến bộ quan trọng cũng như cơ sở hạ tầng hiện có trong không gian AI trong 3-4 tháng qua.
Mặc dù một số tweet có cách diễn đạt không chính xác và thiếu phân tích, tôi muốn làm rõ sự thật. Sau khi đọc bài viết này, bạn sẽ biết nhiều về Bittensor hơn bạn mong đợi. Đây là một báo cáo hơi dài và tôi không có ý dài dòng vì điều này phần lớn là do số lượng lớn hình ảnh và ảnh chụp màn hình. Vui lòng không nhập bài viết vào ChatGPT để lấy tóm tắt, tôi đầu tư rất nhiều thời gian vào việc này và bạn sẽ không hiểu được toàn bộ câu chuyện theo cách đó.
Khi tôi viết báo cáo này, một người bạn (tình cờ là KOL của Twitter về tiền điện tử) đã nói với tôi rằng: “AI + Tiền điện tử = Tương lai của tài chính”. Hãy ghi nhớ điều này khi bạn đọc bài viết này.
Trí tuệ nhân tạo có phải là mảnh ghép cuối cùng để tiền điện tử bắt đầu chiếm lĩnh thế giới hay chỉ là một bước nhỏ hướng tới mục tiêu của chúng ta? Việc tìm ra câu trả lời là tùy thuộc vào bạn, tôi chỉ đưa ra một số điều để bạn suy ngẫm.
Thông tin lai lịch
Theo cách nói của Bittensor, Bittensor về cơ bản là ngôn ngữ để viết nhiều thị trường hàng hóa phi tập trung hoặc mạng con nằm trong một hệ thống mã thông báo thống nhất. Mục tiêu của nó là truyền sức mạnh thị trường kỹ thuật số đến các mặt hàng kỹ thuật số quan trọng nhất của xã hội. --AI.
Sứ mệnh của Bittensor là xây dựng một mạng lưới phi tập trung, thông qua cơ chế khuyến khích độc đáo và kiến trúc mạng con tiên tiến, có thể cạnh tranh với các mô hình trước đó mà “chỉ những công ty khổng lồ như OpenAI mới có thể đạt được”. Bittensor được hình dung tốt nhất như một hệ thống hoàn chỉnh gồm các bộ phận có thể tương tác, một cỗ máy được xây dựng với sự trợ giúp của blockchain để tạo điều kiện thuận lợi hơn cho việc phổ biến khả năng trí tuệ nhân tạo trên chuỗi.
Có hai người chơi chính quản lý mạng Bittensor, họ là người khai thác và người xác nhận. Người khai thác là những cá nhân gửi các mô hình được đào tạo trước lên mạng để đổi lấy một phần phần thưởng. Người xác thực có trách nhiệm xác nhận tính hợp lệ, chính xác của các kết quả đầu ra của mô hình này và chọn ra kết quả đầu ra chính xác nhất để trả về cho người dùng. Ví dụ: nếu người dùng Bittensor yêu cầu chatbot AI trả lời một câu hỏi đơn giản liên quan đến các dẫn xuất hoặc sự kiện lịch sử, câu hỏi sẽ được trả lời bất kể có bao nhiêu nút hiện đang chạy trong mạng Bittensor.
Các bước để người dùng tương tác với mạng Bittensor được mô tả ngắn gọn như sau: người dùng gửi một truy vấn đến trình xác thực, trình xác thực sẽ truyền truy vấn đó đến các thợ mỏ, trình xác thực sau đó xếp hạng các đầu ra của thợ mỏ và đầu ra của thợ mỏ được xếp hạng cao nhất sẽ được gửi quay lại với người dùng.
Tất cả đều rất đơn giản.
Thông qua các biện pháp khuyến khích, các mô hình thường cung cấp đầu ra tốt nhất và Bittensor tạo ra một vòng phản hồi tích cực trong đó các thợ mỏ cạnh tranh với nhau để giới thiệu các mô hình tinh tế, chính xác và hiệu suất cao hơn nhằm giành được thị phần TAO (mã thông báo sinh thái Bittensor) lớn hơn) và thúc đẩy trải nghiệm người dùng tích cực hơn.
Để trở thành người xác thực, người dùng phải là một trong 64 người nắm giữ TAO đầu tiên và đăng ký UID trên bất kỳ mạng con nào của Bittensor (một thị trường kinh tế độc lập cung cấp quyền truy cập vào nhiều dạng trí tuệ nhân tạo khác nhau). Ví dụ: mạng con 1 tập trung vào dự đoán nhãn thông qua lời nhắc văn bản và mạng con 5 tập trung vào việc tạo hình ảnh. Hai mạng con có thể sử dụng các mô hình khác nhau vì nhiệm vụ của chúng rất khác nhau và có thể yêu cầu các thông số, độ chính xác và các tính năng cụ thể khác nhau.
Một khía cạnh quan trọng khác trong kiến trúc của Bittensor là cơ chế đồng thuận Yuma, tương tự như CPU phân phối các tài nguyên có sẵn cho Bittensor trên toàn bộ mạng con. Yuma được mô tả là sự kết hợp giữa PoW và PoS, với chức năng bổ sung là truyền tải và hỗ trợ thông tin ngoài chuỗi. Trong khi Yuma cung cấp phần lớn mạng lưới Bittensor, các mạng con có thể chọn tham gia hoặc không dựa vào sự đồng thuận của Yuma. Các chi tiết cụ thể rất phức tạp và mơ hồ, đồng thời có nhiều mạng con và Github tương ứng khác nhau, vì vậy nếu bạn chỉ muốn hiểu tổng quát, việc biết cách tiếp cận từ trên xuống đối với sự đồng thuận của Yuma sẽ có tác dụng.

Nhưng còn người mẫu thì sao?
Trái với suy nghĩ của nhiều người, Bittensor không đào tạo mô hình của riêng mình. Đây là một quá trình cực kỳ tốn kém mà chỉ các phòng thí nghiệm AI hoặc tổ chức nghiên cứu lớn hơn mới có thể thực hiện được và có thể mất nhiều thời gian. Tôi đã cố gắng đưa ra câu trả lời tuyệt đối về việc liệu đào tạo mô hình có được đưa vào Bittensor hay không, nhưng những phát hiện duy nhất của tôi không có tính thuyết phục.

Cơ chế đào tạo phi tập trung tuy hơi khó phát âm nhưng cũng không khó hiểu. Trình xác thực Bittensor được giao nhiệm vụ “chơi một trò chơi liên tục đánh giá các mô hình do thợ mỏ tạo ra trên tập dữ liệu không gắn nhãn T-Token của Falcon Refined Web 6” để đánh giá từng mô hình dựa trên hai tiêu chí: dấu thời gian và tổn thất so với các mô hình khác. Hàm mất mát là một thuật ngữ học máy được sử dụng để mô tả sự khác biệt giữa giá trị dự đoán và giá trị thực tế trong một loại mô phỏng nhất định, biểu thị mức độ lỗi hoặc độ không chính xác của dữ liệu đầu vào và đầu ra của mô hình.
Về chức năng mất, đây là hiệu suất mới nhất của sn 9 (mạng con có liên quan) mà tôi lấy từ Discord ngày hôm qua, hãy nhớ rằng tổn thất tối thiểu không nhất thiết có nghĩa là tổn thất trung bình:
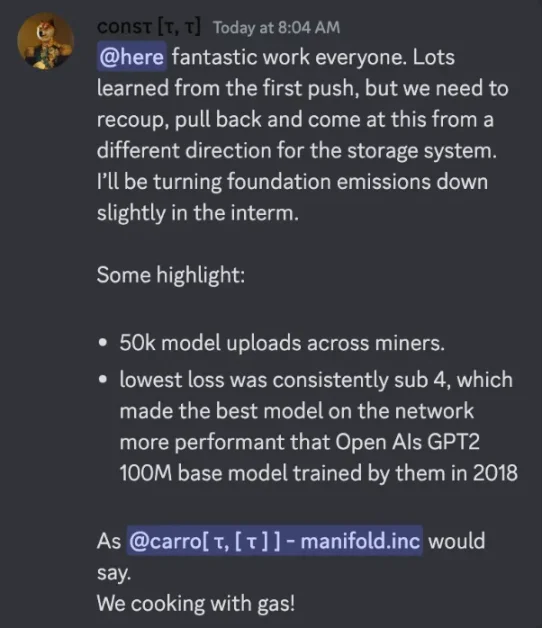
“Nếu bản thân Bittensor không đào tạo mô hình thì nó có thể làm được gì nữa?!”
Trên thực tế, quá trình “sáng tạo” mô hình ngôn ngữ lớn (LLM) được chia làm 3 giai đoạn chính là đào tạo, tinh chỉnh và học theo ngữ cảnh (thêm một chút lý luận).
Trước khi chuyển sang một số định nghĩa cơ bản, hãy xem bài viết tháng 6 năm 2023 của Sequoia Capital về LLMBáo cáo, phát hiện của họ là: Thông thường, ngoài việc sử dụng LLM API, 15% công ty đã xây dựng các mô hình ngôn ngữ tùy chỉnh từ đầu hoặc dựa trên các thư viện nguồn mở. Việc đào tạo mô hình tùy chỉnh đã tăng lên đáng kể chỉ từ vài tháng trước. Điều này đòi hỏi bạn phải Tính toán ngăn xếp, trung tâm mô hình, lưu trữ, khung đào tạo, theo dõi thử nghiệm, v.v. từ các công ty được yêu thích như Ôm mặt, Tái tạo, Foundry, Tecton, Trọng lượng Xu hướng, PyTorch, Quy mô, v.v.
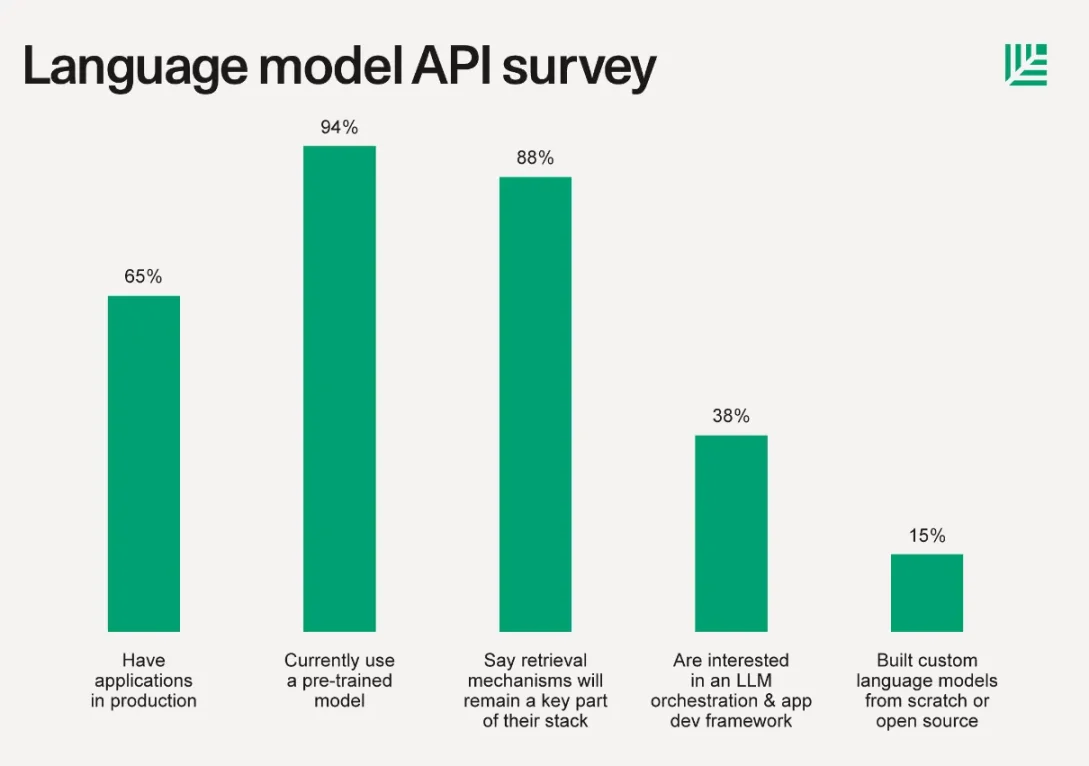
Xây dựng một mô hình từ đầu là một nhiệm vụ khó khăn và 85% người sáng lập và nhóm được khảo sát không sẵn lòng thực hiện nó. Khối lượng công việc tự lưu trữ, theo dõi kết quả, tạo hoặc nhập các kịch bản đào tạo phức tạp và nhiều nhiệm vụ khác thật khó khăn khi hầu hết các công ty khởi nghiệp và nhà phát triển độc lập chỉ muốn tận dụng các mô hình ngôn ngữ lớn trong các ứng dụng bên ngoài hoặc dịch vụ dựa trên phần mềm quá lớn. Đối với 99% ngành công nghiệp AI, việc tạo ra thứ gì đó có thể so sánh được với GPT-4 hoặc Llama 2 là không khả thi.
Đây là lý do tại sao các nền tảng như Ôm mặt rất phổ biến vì bạn có thể tải xuống các mô hình đã được đào tạo từ trang web của họ, một quy trình rất quen thuộc và phổ biến đối với những người làm trong ngành AI.
Việc tinh chỉnh khó hơn nhưng phù hợp với những ai muốn cung cấp các ứng dụng hoặc dịch vụ dựa trên mô hình ngôn ngữ lớn trong một phân khúc cụ thể. Đây có thể là một công ty khởi nghiệp dịch vụ pháp lý đang phát triển một chatbot với mô hình được tinh chỉnh dựa trên nhiều dữ liệu và ví dụ cụ thể của luật sư hoặc một công ty khởi nghiệp công nghệ sinh học đang phát triển một mô hình cụ thể dựa trên những thông tin có thể liên quan đến công nghệ sinh học.

Dù mục đích là gì, tinh chỉnh là việc kết hợp sâu hơn tính cách hoặc kiến thức chuyên môn vào mô hình của bạn, làm cho mô hình phù hợp hơn và chính xác hơn khi thực hiện nhiệm vụ. Mặc dù không thể phủ nhận nó hữu ích và dễ tùy chỉnh hơn nhưng mọi người đều đồng ý rằng nó khó, kể cả a16znghĩ:

Mặc dù Bittensor không thực sự đào tạo mô hình, nhưng những người khai thác gửi mô hình của riêng họ lên mạng yêu cầu tinh chỉnh các mô hình dưới một số hình thức, mặc dù thông tin này không được công bố rộng rãi (hoặc ít nhất là khó xác minh). Công cụ khai thác giữ bí mật cấu trúc mô hình và chức năng của mình để bảo vệ lợi thế cạnh tranh của mình, mặc dù một số có thể truy cập được.
Hãy lấy một ví dụ đơn giản: nếu bạn đang tham gia một cuộc thi với giải thưởng 1 triệu đô la và mọi người đang cạnh tranh để xem ai có LLM hoạt động tốt nhất, nếu tất cả các đối thủ cạnh tranh của bạn đang sử dụng GPT-2, bạn có Tiết lộ rằng bạn đang sử dụng GPT không -4? Mặc dù tình hình thực tế phức tạp hơn ví dụ này minh họa nhưng nó cũng không khác mấy. Những người khai thác được khen thưởng dựa trên độ chính xác đầu ra của họ, điều này mang lại cho họ lợi thế so với những người khai thác tinh chỉnh ít mô hình hơn hoặc các mô hình có hiệu suất trung bình kém hơn.
Tôi đã đề cập đến việc học theo ngữ cảnh trước đây và đây có lẽ là phần thông tin cuối cùng không phải Bittensor mà tôi sẽ đề cập, nhưng học theo ngữ cảnh là một quá trình được xác định rộng rãi để hướng dẫn các mô hình ngôn ngữ đạt được kết quả đầu ra mong muốn hơn. Suy luận là quá trình mà một mô hình liên tục trải qua khi đánh giá đầu vào và kết quả huấn luyện của nó có thể ảnh hưởng đến độ chính xác của nhãn đầu ra. Mặc dù việc đào tạo rất tốn kém nhưng nó chỉ xảy ra khi mô hình đã sẵn sàng đạt đến cấp độ đào tạo do nhóm chỉ định trong quá trình tạo mô hình. Việc suy luận luôn diễn ra và nhiều dịch vụ bổ sung khác nhau được sử dụng để tạo điều kiện thuận lợi cho quá trình suy luận.
Trạng thái Bittensor
Với một số thông tin cơ bản, tôi sẽ khám phá một số chi tiết về hiệu suất mạng con Bittensor, chức năng hiện tại và các kế hoạch trong tương lai. Thành thật mà nói, thật khó để tìm được những bài viết chất lượng về chủ đề này. May mắn thay, các thành viên cộng đồng Bittensor đã gửi cho tôi một số tin nhắn, nhưng ngay cả khi đó, việc đưa ra ý kiến vẫn tốn rất nhiều công sức. Tôi ẩn nấp trong Discord của họ để tìm kiếm câu trả lời và trong quá trình đó, tôi nhận ra mình đã là thành viên được khoảng một tháng nhưng chưa xem bất kỳ kênh nào (tôi chưa bao giờ sử dụng Discord, nhiều Telegram và Slack hơn).
Dù sao đi nữa, tôi quyết định xem xét tầm nhìn ban đầu của Bittensor và đây là những gì tôi tìm thấy trong báo cáo trước đó:

Tôi sẽ đề cập đến nó trong một vài đoạn tiếp theo, nhưng lý thuyết về khả năng kết hợp không có giá trị. Đã có một số nghiên cứu về chủ đề này, ảnh chụp màn hình trước đó xuất phát từ việc xác định mạng Bittensor là mô hình hỗn hợp thưa thớt (khái niệm này là nghiên cứu năm 2017giấyđã nộp).
Bittensor có rất nhiều mạng con nên tôi cảm thấy cần phải dành toàn bộ phần cho chúng trong báo cáo này. Dù bạn có tin hay không, mặc dù những điều này rất quan trọng đối với tính hữu ích của web và làm nền tảng cho tất cả các công nghệ, Bittensor không có phần dành riêng trên trang web của mình để mô tả những điều này và cách chúng hoạt động. Tôi thậm chí còn hỏi trên Twitter, nhưng có vẻ như bí mật của mạng con chỉ có những người lang thang hàng giờ trên Discord và tự mình tìm hiểu hoạt động của từng mạng con mới hiểu được. Bất chấp khối lượng công việc trước mắt, tôi vẫn làm được một số việc.
Subnet 1 (thường được viết tắt là sn 1) là mạng con lớn nhất trong mạng Bittensor và chịu trách nhiệm về dịch vụ tạo văn bản. Trong số 10 trình xác nhận hàng đầu của sn 1 (tôi sử dụng cùng thứ hạng top 10 cho các mạng con khác), có khoảng 4 triệu TAO được đặt cược, tiếp theo là sn 5 (chịu trách nhiệm tạo hình ảnh), có khoảng 3,85 triệu TAO Pledge. Nhân tiện, tất cả dữ liệu này có sẵn tạiTaoStatsđược tìm thấy trên .
Mạng con đa phương thức (sn 4) có khoảng 3,4 triệu TAO, sn3 (data Scraping) có khoảng 3,4 triệu TAO và sn 2 (đa phương thức) có khoảng 3,7 triệu TAO. Một mạng con khác đã phát triển nhanh chóng gần đây là sn 11, chịu trách nhiệm đào tạo văn bản và có số lượng cam kết TAO tương tự như sn 1.
Sn 1 cũng là công ty dẫn đầu tuyệt đối về hoạt động khai thác và xác thực, với hơn 40/128 trình xác thực đang hoạt động và 991/1024 công cụ khai thác đang hoạt động. Sn 11 thực sự có nhiều công cụ khai thác nhất trong tất cả các mạng con, với 2017/2048. Biểu đồ bên dưới mô tả chi phí đăng ký mạng con trong một tháng rưỡi qua:
Chi phí hiện tại để đăng ký một mạng con là 182,12 TAO, giảm đáng kể so với mức đỉnh 7.800 TAO trong tháng 10, mặc dù tôi không hoàn toàn chắc chắn con số đó là chính xác. Bất chấp điều đó, với hơn 22 mạng con đã đăng ký và sự chú ý ngày càng tăng của Bittensor, chúng ta có thể sẽ thấy nhiều mạng con được đăng ký hơn trong thời gian tới. Một số mạng con này dường như phải mất một thời gian mới có được lực kéo.
Đối với các mạng con khác, sn 9 là một mạng con thú vị dành riêng cho đào tạo:

Sau đây là mô tả của BittensorThu thập mạng conhướng dẫn của:

Mô hình mạng con rất độc đáo và là ví dụ về một kỹ thuật phổ biến trong nghiên cứu máy học được gọi là hỗn hợp các chuyên gia (MoE), trong đó mô hình được chia thành các phần và được cung cấp các nhãn riêng lẻ, thay vì được giao toàn bộ nhiệm vụ. Điều này thật thú vị đối với tôi vì Bittensor không phải là một mô hình thống nhất mà thực sự là một mạng lưới các mô hình được truy vấn theo cách bán ngẫu nhiên. Một ví dụ về quy trình này là BitAPI, một sản phẩm được xây dựng trên sn 1 lấy mẫu ngẫu nhiên 10 công cụ khai thác hàng đầu được người dùng trong nước truy vấn. Mặc dù có thể có hàng chục hoặc thậm chí hàng trăm thợ mỏ trong bất kỳ mạng con nhất định nào, nhưng những mô hình hoạt động tốt nhất sẽ nhận được phần thưởng lớn hơn.
Hiện tại, việc kết hợp hoặc tổng hợp nhiều mô hình để thêm hoặc xếp chồng chức năng là không khả thi. Đây không phải là cách các mô hình ngôn ngữ lớn hoạt động. Tôi đã cố gắng lý luận với các thành viên trong cộng đồng, nhưng tôi nghĩ điều quan trọng cần lưu ý là, như hiện tại, Bittensor không phải là một ví dụ về một bộ sưu tập mô hình thống nhất, chỉ là một mạng lưới các mô hình với các khả năng khác nhau.
Một số người đã so sánh Bittensor với các nhà tiên tri trên chuỗi có quyền truy cập vào các mô hình ML. Bittensor tách logic cốt lõi của blockchain khỏi việc xác minh mạng con, chạy mô hình ngoài chuỗi để chứa nhiều dữ liệu hơn và chi phí tính toán cao hơn, từ đó đạt được các mô hình mạnh mẽ hơn. Bạn có thể nhớ lại rằng quy trình duy nhất được thực hiện trên chuỗi là suy luận. Xem bên dướinội dungTìm hiểu lời giải thích của Bittensor:
Tôi nghĩ nhiều người trong cộng đồng quá tập trung vào việc cố gắng thuyết phục mọi người rằng Bittensor sẽ thay đổi thế giới, trong khi thực tế họ chỉ đang đạt được tiến bộ trong việc cố gắng thay đổi cách tương tác giữa trí tuệ nhân tạo và tiền điện tử. Khó có khả năng họ có thể biến toàn bộ mạng lưới các mô hình tải lên của thợ mỏ thành một siêu máy tính cực kỳ thông minh - đó không phải là cách hoạt động của máy học. Ngay cả những mẫu máy có hiệu suất tốt nhất và đắt nhất hiện nay vẫn còn phải mất nhiều năm nữa mới đạt được định nghĩa về trí tuệ nhân tạo tổng quát (AGI).
Khi cộng đồng máy học tiếp tục lặp đi lặp lại và các tính năng mới được triển khai, định nghĩa về AGI thường khác nhau, nhưng ý tưởng cơ bản là AGI có thể suy luận, suy nghĩ và học hỏi chính xác như con người. Câu đố cốt lõi xuất phát từ việc các nhà khoa học phân loại con người là những sinh vật có ý thức và ý chí tự do, điều này rất khó định lượng ở con người chứ đừng nói đến hệ thống mạng lưới thần kinh mạnh mẽ.
Như hiện tại, mạng con là một cách độc đáo để chia nhỏ các nhiệm vụ khác nhau liên quan đến các ứng dụng dựa trên AI và cộng đồng và các nhóm có trách nhiệm thu hút các nhà xây dựng muốn tận dụng các khả năng cốt lõi này của Mạng Bittensor.
Điều đáng nói thêm ở đây là Bittensor rất hiệu quả trong lĩnh vực học máy ngoài tiền điện tử. Opentensor và Cerebras đã phát hành LLM nguồn mở BTLM-3 b-8 k vào đầu tháng 7 năm nay. Kể từ đó, BTLM đã được tải xuống hơn 16.000 lần trên Hugging Face và nhận được những đánh giá rất tích cực.
Một số người nói rằng do cấu trúc nhẹ của BTLM, BTLM-3 b được xếp hạng cao cùng loại với Mistral-7 b và MPT-30 b, trở thành mô hình tốt nhất trên mỗi VRAM. Dưới đây là biểu đồ từ cùng một tweet liệt kê các mô hình và phân loại khả năng truy cập dữ liệu của chúng, trong đó BTLM-3 b nhận được xếp hạng khá:
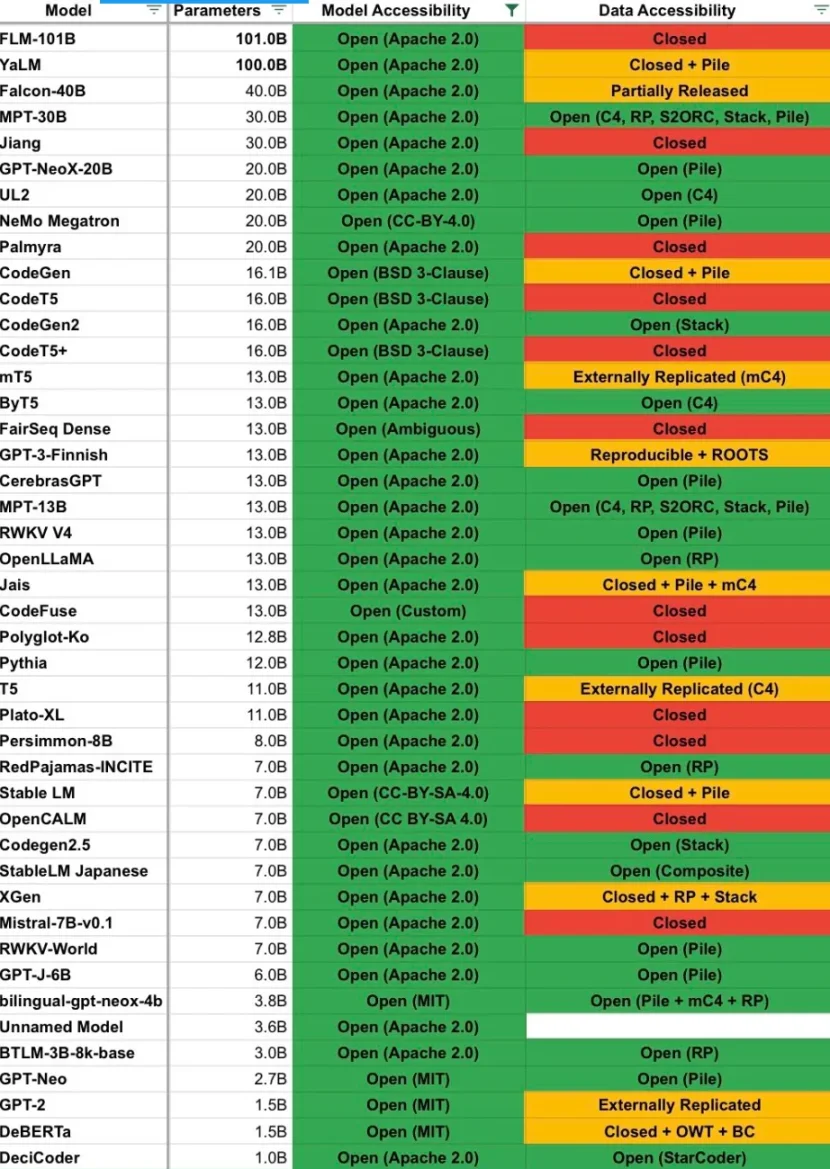
Tôi đã nói trên Twitter rằng Bittensor không làm bất cứ điều gì để tăng tốc nghiên cứu AI, vì vậy tôi nghĩ việc thừa nhận sai lầm của mình ở đây là điều đúng đắn. Ngoài ra, tôi nghe nói rằng BTLM-3 b được sử dụng để xác minh trong một số trường hợp vì nó rẻ và chạy nhanh trên hầu hết phần cứng.
TAO dùng để làm gì?
Đừng lo lắng, tôi không quên mã thông báo.
Bittensor mượn rất nhiều cảm hứng từ Bitcoin, nhưng cũng lấy từ lối chơi trong sách giáo khoa OG và kết hợp cấu trúc kinh tế mã thông báo rất giống nhau, tức là tối đa 21 triệu TAO và cơ chế giảm một nửa cứ sau 10,5 triệu khối. Tính đến thời điểm viết bài này, số lượng TAO đang lưu hành là khoảng 5,6 triệu, với giá trị thị trường gần 800 triệu USD. Việc phân phối TAO được coi là cực kỳ công bằng và Bittensor nàyBáo cáoLưu ý rằng những người ủng hộ sớm không nhận được bất kỳ mã thông báo nào, mặc dù rất khó để xác minh tính xác thực nhưng chúng tôi tin tưởng vào nguồn của mình.
TAO vừa là mã thông báo phần thưởng vừa là mã thông báo truy cập của mạng Bittensor. Người nắm giữ TAO có thể đặt cọc, tham gia quản trị hoặc sử dụng TAO của họ để xây dựng các ứng dụng trên mạng Bittensor. 1 TAO được đúc cứ sau 12 giây và các mã thông báo mới được đúc sẽ được phân bổ đồng đều cho người khai thác và người xác thực.
Theo tôi, nền kinh tế mã thông báo của TAO dễ dàng hình dung ra một thế giới trong đó việc giảm khối lượng phát hành thông qua việc giảm một nửa dẫn đến sự cạnh tranh ngày càng tăng giữa các thợ mỏ, dẫn đến các mô hình chất lượng cao hơn và trải nghiệm người dùng tổng thể tốt hơn. Tuy nhiên, cũng có một vấn đề ở đây, đó là phần thưởng nhỏ hơn sẽ có tác dụng ngược và thay vì thu hút sự cạnh tranh mạnh mẽ sẽ dẫn đến số lượng mô hình được triển khai hoặc thợ đào cạnh tranh trì trệ.
Tôi có thể tiếp tục về tiện ích token của TAO, triển vọng giá và động lực tăng trưởng, nhưng báo cáo nói trên thực hiện khá tốt vấn đề này. Hầu hết Twitter về tiền điện tử đã xác định rằng có một câu chuyện rất chắc chắn đằng sau Bittensor và TAO, và không có gì tôi có thể thêm vào thời điểm này sẽ làm tăng thêm phần kem trên bánh. Từ góc độ bên ngoài, tôi có thể nói rằng đây là những nền kinh tế mã thông báo khá tốt và không có gì khác thường. Tuy nhiên, tôi nên đề cập rằng việc mua TAO hiện rất khó khăn vì nó chưa được niêm yết trên hầu hết các sàn giao dịch. Tình trạng này có thể thay đổi sau 1-2 tháng nữa và tôi sẽ rất ngạc nhiên nếu Binance không sớm niêm yết TAO.
tiềm năng
Tôi chắc chắn là một fan hâm mộ của Bittensor và hy vọng họ nhận ra sứ mệnh táo bạo của mình. Là nhóm tại Bittensor Paradigmbài báoNhư đã nêu trong , Bitcoin và Ethereum mang tính cách mạng vì chúng dân chủ hóa khả năng tiếp cận tài chính và biến ý tưởng về thị trường kỹ thuật số hoàn toàn không cần cấp phép trở thành hiện thực. Bittensor cũng không ngoại lệ và nhằm mục đích dân chủ hóa các mô hình trí tuệ nhân tạo trong các mạng thông minh rộng lớn. Bất chấp sự ủng hộ của tôi, rõ ràng là họ vẫn còn cách xa những gì họ muốn đạt được, điều này đúng với hầu hết các dự án được xây dựng bằng tiền điện tử. Đây là một cuộc chạy marathon, không phải chạy nước rút.
Nếu Bittensor muốn giữ vị trí dẫn đầu, họ cần tiếp tục thúc đẩy sự cạnh tranh và đổi mới thân thiện giữa các thợ mỏ đồng thời mở rộng khả năng của kiến trúc mô hình lai thưa thớt, ý tưởng MoE và khái niệm trí tuệ tổng hợp theo cách phi tập trung. Chỉ thực hiện tất cả những điều này đã khó, việc thêm mã hóa vào danh sách kết hợp khiến việc này càng khó khăn hơn.
Bittensor vẫn còn một chặng đường dài phía trước. Mặc dù các cuộc thảo luận xung quanh TAO đã gia tăng trong những tuần gần đây nhưng tôi không nghĩ rằng hầu hết cộng đồng tiền điện tử đều nhận thức đầy đủ về cách thức hoạt động của Bittensor. Có một số câu hỏi rõ ràng không có giải pháp dễ dàng, một số trong đó là: a) liệu có thể suy luận quy mô lớn chất lượng cao hay không, b) vấn đề thu hút người dùng và c) liệu việc theo đuổi mục tiêu tổng hợp ngôn ngữ lớn có hợp lý hay không các mô hình.
Dù bạn có tin hay không thì việc hỗ trợ câu chuyện về tiền tệ phi tập trung thực sự là một thách thức khá lớn, mặc dù những tin đồn về ETF đang khiến việc này trở nên dễ dàng hơn một chút.
Việc xây dựng một mạng lưới phi tập trung gồm các mô hình thông minh lặp đi lặp lại và học hỏi lẫn nhau nghe có vẻ quá tốt đến mức khó tin và một phần lý do là như vậy. Trong những hạn chế hiện tại của cửa sổ nền và mô hình ngôn ngữ lớn, một mô hình không thể tự cải thiện nhiều lần cho đến khi đạt đến điểm mà với AGI, ngay cả những mô hình tốt nhất vẫn còn hạn chế. Tuy nhiên, tôi nghĩ việc xây dựng Bittensor như một nền tảng lưu trữ LLM phi tập trung với các ưu đãi kinh tế mới và khả năng kết hợp tích hợp không chỉ là một điều tích cực mà nó thực sự là một trong những thử nghiệm thú vị nhất về tiền điện tử hiện nay.
Việc tích hợp các ưu đãi tài chính vào hệ thống AI có những thách thức riêng và Bittensor nói rằng nếu người khai thác hoặc người xác thực cố gắng đánh lừa hệ thống dưới bất kỳ hình thức nào, họ sẽ điều chỉnh các ưu đãi theo từng trường hợp cụ thể. Đây là một ví dụ từ tháng 6 năm nay, khi số lượng phát hành token giảm 90%:

Điều này hoàn toàn có thể dự đoán được trong một hệ thống blockchain, vì vậy đừng giả vờ rằng Bitcoin hoặc Ethereum sẽ hoàn hảo 100% trong suốt vòng đời của nó.
Việc áp dụng tiền điện tử trong lịch sử là một viên thuốc khó nuốt đối với người ngoài và trí tuệ nhân tạo cũng gây tranh cãi không kém, nếu không muốn nói là nhiều hơn. Việc kết hợp cả hai sẽ tạo ra thách thức cho bất kỳ ai trong việc duy trì sự phát triển và hoạt động của người dùng, việc này sẽ mất một thời gian. Nếu Bittensor cuối cùng có thể đạt được mục tiêu của các mô hình ngôn ngữ lớn tổng hợp thì đây có thể là một điều rất quan trọng.


