
引入自动回归市场 (ARMs):半同质资产的新价格发现机制
DAOrayaki DAO研究奖金池:
资助地址:0xCd7da526f5C943126fa9E6f63b7774fA89E88d71
投票进展:DAO Committee 3/7通过
赏金总量:100USDC
研究种类:DAO, semi-fungible assets
原文作者: BlockScience
贡献者: Natalie, DAOctor @DAOrayaki
原文:Introducing Automated Regression Markets (ARMs): A New Price Discovery Mechanism for Semi-Fungible Assets
BlockScience 正在研究和开发一种用于高维、半可替代资产的新型价格发现机制。这种被称为自动回归市场 (ARM) 的机制在各种市场中具有多种潜在应用;我们的第一次探索将深入探讨可持续价值能源市场的用例,例如可再生能源信用 (REC) 和碳抵消/清除信用 (CORC)市场。
与Hedera Hashgraph和HBAR 基金会的DLT 行业领导者合作,我们正在开展一项研究项目,以对能源信用 ARM 进行建模和模拟。我们将研究初级做市商的价格发现潜力,以及具有多种属性的资产的供需行为。这是该联合研发工作系列文章中的第一篇。
什么是ARM?
在我们的论文“可替代性的实用理论”中,我们介绍了自动回归市场 (ARM) 的概念。ARM 的想法是利用机器学习 (ML) 模型和自动做市商 (AMM)之间的数学相似性,为非商品资产提供动态价格发现。商品是一组对象,因此影响其评估价值和需求的属性是等价的。总之,商品是可以互换的。这个概念是现有 AMM 工作方式的核心——汇集可替代资产并根据其算法曲线发现价格。¹
ARM 扩展到 AMM 之外,允许在主要市场 ARM 上买卖半可替代资产,例如包含不同属性的能源信用或碳抵消/清除。这为高度复杂的属性安排提供了有效的价格发现,例如(对于能源信用)能源生产类型、地理位置等。
这项工作中最重要的观察结果之一是,两个项目的可替代性取决于所提供的这些项目的属性以及评估这些项目的语境。这一观察有助于我们更好地理解由非商品(或“部分可替代”,参见下文)商品组成的市场的供需关系。
商品属性表征供应方,如果商品具有不同的属性,我们就说它们是可区分的。评估项目属性的语境表征了需求方。如果商品属性的差异不影响他们的评价,从而不影响对这些商品的需求,我们就说商品在特定的需求环境中是可替代的。部分可替代商品的可替代性随需求环境而变化。例如,如果一家企业想要购买在美国太平洋西北部生产的太阳能信贷,买方想要的资产将不能替代在亚洲生产的信贷。通过生产地点或生产类型等属性识别资产的能力不仅对许多购买者来说是必需的,而且可能对这些资产的估值产生巨大影响。
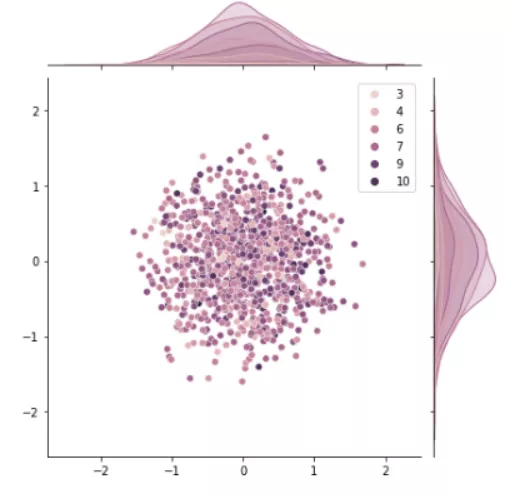
该图表示模拟属性的前两个主成分分布的散点图和直方图。自动回归市场利用自适应子空间检测和递归回归来动态(重新)发现哪些属性组合是有价值的。
半同质价格发现的现有案例
乍一看,能够买卖部分可替代的非商品的市场的自动化似乎有些牵强。然而,在工业界和学术界2,市场和 ML 之间的融合是有优先权的。住房市场相对自然地适合半同质商品这一分类。房屋都是可区分的,但是当它们的属性足够相似时,它们可能被认为是可替代的(在购买之前 -所有权会影响可替代性)。由于这些原因,在线房地产市场提供商 Zillow 有可能越来越依赖其 AI 应用程序“ Zestimate ”来推动购买决策。
Zestimate 可能是最早的混合智能示例之一,它既可以从市场活动中学习,也可以创建市场活动,但观察该模型的执行性质非常重要。Zillow 已开始基于其 Zestimate提供房屋报价,这自然会影响市场。但是,Zestimate 不仅仅估算房屋的价格,它还通过影响买卖双方对房屋价值的信念来创造价格。通过这种方式,Zestimate 一直在充当做市商,甚至在 Zillow 根据其估计进入购买房屋的业务之前。
虽然这些技术的创新潜力巨大,但在将机器学习动态引入市场时,考虑可能的系统性和二阶效应以及潜在的意外后果始终很重要。在这个问题的学术方面,领先的 AI 研究员 Michael I. Jordan 为我们描绘了推荐引擎和市场之间协同作用的图景。他特别指出了天真地将推荐引擎应用于稀缺资源所造成的危害。例如,向许多购物者推荐有限供应的商品会人为地夸大相对于某些买家而言可能具有替代性甚至优越性的商品的需求。同样,为许多司机推荐低带宽快捷方式的导航应用程序可能会造成严重的拥堵。
AI 算法的本质是将丰富的信息压缩成简洁的形式,但市场反而是丰富信息的生成器,因为它利用了广泛买家群的异质性。如果允许 AI 算法主导系统,它将变得陈旧,因为强硬的推荐引擎会降低产品的多样性,而消费者选择的丧失又会降低市场从消费者那里获取偏好信息的能力。我们可以在工程过程中通过严格的测试和设计验证来创建更好的系统。
ARM 的类和实例
随着我们继续研究 ARM 模型,我们需要明确我们的目标。我们的目标是平衡机器学习的压缩能力和市场的发现能力,以促进新形式的高维能源市场(以及其他用例)。正如我们在可替代性论文中提到的,最好在在线学习的背景下正式理解这一点。我们将经济博弈作为估计器和将常数函数做市商 (CFMM)作为预言机的工作表明,某些类型的智能算法定价模型可以被解释为信号处理操作,它学习市场如何为商品和服务定价(在这些情况下为商品) ——“语境商品”。
ARM 研发的前进道路要求我们将其视为一个“类”,其中各个“实例”适合其特定领域。在机器学习中,这包括模型选择、特征工程、元参数优化、集成和数据科学家应用的其他定制,以将特定模型适合特定问题域。对于 AMM,这包括选择特定的设计模式,例如 Uniswap、Balancer、Curve 等。这些不同的 CFMM 具有不同的基础数学不变量的特征。但即使在选择了一类 AMM 之后,仍有一些独特的实例具有自己的资产和其他元参数,例如费用和权重。
必须承认这种类/实例关系是 ARM 研究的前沿扩展。由于其与 ML 的相似性,我们理解开发和维护 ARM 的难度可能会有很大差异,具体取决于模型要综合的信息。BlockScience 正在与Hedera Hashgraph 和 HBAR 基金会的可持续发展计划合作,专门为能源信用市场设计一个 ARM 实例,因为能源信用资产为具有多种属性的项目提供了一个很好的用例,并且价值会受到上下文的极大影响。
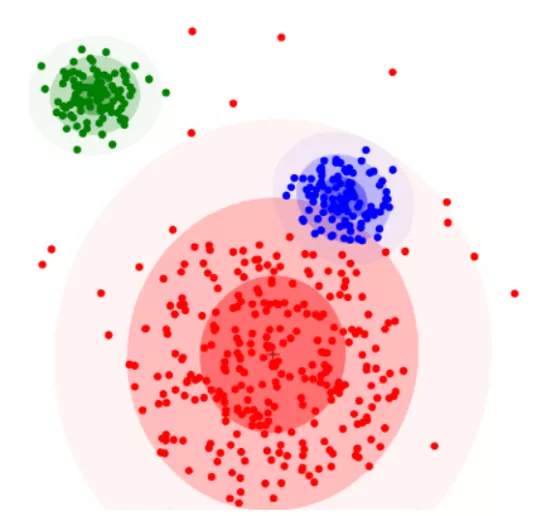
按属性进行 ML 数据聚类的示例。在 ARM 中,像这样的集群可以代表可再生能源信用属性,并用于促进半可替代资产的供需环境的“匹配”。(来源:https : //en.wikipedia.org/wiki/Cluster_analysis)
为什么能源和碳市场是 ARM 的绝佳用例
目前,批量购买和出售无法区分的能源信用额度,几乎没有透明度和可审计性。可再生能源市场也是高度人工化的,经纪人交易的碳抵消/清除信用和可再生能源信用可能具有非常不同的背景。虽然这些资产被当作商品(可替代)进行交易,但实际上,由于能源的生产地点和方式、生产手段、所用设备的数量和质量,它们在市场上的价值可能大不相同,以及它们属性的其他方面以及如何在不同的上下文中评估这些属性。
有了 ARM,这些资产可以更精细地分离,因为市场或需求方可以决定这些半同质资产的不同价格。能源资产的购买者通常基于不同司法管辖区的法律要求,需要更多的信息和供应方的可见性。参与这些市场的人们希望了解哪些属性受到高度追捧,哪些属性更为普遍,以便在满足要求的同时行使购买力。
在 ARM 中,半可替代的商品——各种属性的“捆绑”——根据市场条件和生产环境而具有不同的权重。这将为市场提供更好的信息,以便在供需参数之间进行匹配——换言之,更有效的市场。此外,此功能可以通过在公共分类账本上发现能源和碳信用,并通过验证链接到其可审计来源来提供价值。
确保 CORC 或 REC 是独一无二的,并在链上代表碳抵消/去除或链下创建的能源资产,是这一市场创新的一个非常重要的方面。Hedera 生态系统和 HBAR 基金会可持续发展计划的核心部分是Guardian ,这是一个完全可审计的解决方案,可以验证能源资产的属性。Guardian3 为链下数据提供质量证明,包括去中心化身份、政策驱动的行动和公平的交易顺序。这些属性提供了消除公认的数据质量问题(例如资产重复计算)的方法,这些问题会混淆供需,并将成为使用 ARM 实现 CORC 和 REC 自动化的研究和开发的核心。
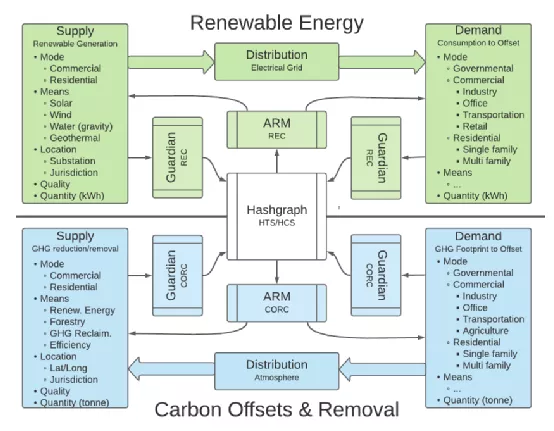
可再生能源信贷市场供需双方可能存在的多个属性或参数的说明。顶部(绿色框)代表 REC,底部(蓝色)代表 CORC。ARM 可以将私人偏好信号提取为公共价格信号,同时跟踪潜在的信号变化。ARM 可以“学习”以做出更准确的定价预测,并提供市场供需双方的自动匹配。在市场估值的背景下,同样的代币对于 ARM 来说是半可替代的。
ARMing 能源市场的潜在收益和全球影响
到2026 年,全球能源即服务市场规模预计将超过1066 亿美元,随着 CORC 和 REC 的重要性日益增加,这些市场的创新时机已经成熟。ARM 机制可能对能源信贷市场产生巨大影响,并通过将自动化做市商的技术与链上代表的现实世界可变资产联系起来,打开一个充满可能性的新世界。
ARM 可以提供自动化,允许大规模扩展和扩展能源市场和交易,加速市场发展并为期货市场提供潜力。对于个人、较小的能源生产商或合作社来说,成本也可以降低,因为他们可以更容易地聚合分散的发电网络,以提供抵押品或代币化资产,以换取融资。随着更高效和不断扩大的市场以及对能源生产和属性的更高可见性,将有更大的动力来改善和投资于满足更高或更有价值的标准或市场要求的标准的基础设施。本地化的更多可见性还可以使本地生产的价值保持在这些边界内,而不是被提取到更大的市场。
然而,与任何技术或创新一样,还有许多尚未探索的连锁反应——任何新领域都会带来潜在的意外后果和新市场机制的系统性影响。如前所述,我们的目标是在 ML 的压缩能力和市场的发现能力之间取得平衡。作为工程师,总是有设计权衡。这就是建模和仿真工作极其重要的原因,也是我们使用 cadCAD 来优化复杂系统设计的原因。

使用机器学习可视化高维空间(来源:https : //www.youtube.com/watch?v=wvsE8jm1GzE)
使用 cadCAD 对 ARM 建模
cadCAD(复杂自适应动力学计算机辅助设计的简称)是一个开源建模框架,用于使用计算机研究、验证和设计复杂系统。这有助于个人或组织就如何最好地修改复杂系统或与复杂系统交互以实现其预期目标做出明智的、经过严格测试的决策。
为了开始研究 ARM是如何对供需相互作用进行合理预测,并允许跨初级市场的多属性能源信用进行价格发现的,我们将开发一个对照实行的 ARM 算法。连同从能源信贷市场收集的数据,此对照组实施将创建市场活动模拟,以测试 ARM 在此类市场中的信号处理能力。具体来说,我们将:
1)证明能源信用市场对机器学习应用的适用性
2)执行会计规则,例如,以确保对手不能通过向 ARM 充斥无法出售的能源信用来简单地使其破产。
与此同时,Hedera 生态系统正在开发部署 ARM 所需的核心应用逻辑,在 Hedera 公共分类账上执行业务逻辑和会计,例如他们最近开源的 Guardian,用于根据现实世界的动作验证链上声明。
虽然我们将发展技术要求以支持能源信用 ARM 的部署,但所得的结果将推广到广泛的部分可替代的、两侧市场应用程序在其基础设施上。Hedera 生态系统不仅专注于部署完全自定义的 ARM 实例,还为其基础架构创建了 ARM应用程序设计模式。这将使应用程序能够专注于其 ARM 设计的数据科学方面,并信任其市场设计对 Hedera 网络的部署和实施。
未来,可以研究诸如次级效应、系统级激励和机制的其他潜在参数等主题,以深入了解 ARM 如何“学习”和运行。
参考
1. 在 AMM 中,手动做市商的订单簿被资产池和一个不变的、保值的功能所取代,该函数将池中的每个资产与其他资产联系起来。资产池是市场实现流动性的手段。不变函数是市场决定资产相对价值的方式。交易是一种集合资产与另一种集合资产的单独交换。不变函数计算后一资产将被交换为前一资产的数量,从而保持不变。AMM 假设给定池中的资产是可互换的。可替代资产可以完全用两个属性来描述,类型和数量。换句话说,在任何情况下,可替代资产的唯一属性是其类型和数量。在 AMM 中,资产的类型决定了资产所属的池。资产的数量决定了涉及整体流动性或特定交易所交易的资产数量。
Token 工程研究员 Lisa Tan 讲解:https :
//www.youtube.com/watch?v=842acSWmBC4&t=1093s
DeFi 研究员和图形艺术家 Finematics 的 Visual Explainer:https : //www.youtube.com/watch? v = cizLhxSKrAc
2. Oladunni, T. 和 S. Sharma (2016),“Hedonic Housing Theory - A Machine Learning Investigation”,2016 年第 15 届 IEEE 机器学习和应用国际会议 (ICMLA),第 522-527 页。doi:10.1109/ICMLA.2016.0092
Shorish, J. (2019),“加密货币代币的享乐定价”,数字金融卷。1,第 163-189 页。doi:10.1007/s42521–019–00005-y
3. https://github.com/hashgraph/guardian


